
Fala meu grande amigo, tudo bem com você? No post de hoje vou trazer um assunto que pra mim é novidade, pois nunca tinha feito a integração com uma API usando o Azure Data Factory, tudo que vou falar aqui sempre fiz utilizando o Python.
A ideia de escrever esse post surgiu através de uma conversa com o meu amigo Pedro Ivo, um excelente profissional desse fantástico mundo dos dados.
Durante uma troca de mensagem ele perguntou se eu tinha algum material ou documentação que falava sobre a utilização do Azure Data Factory para integrar com uma API.

Falei pra ele que não e que também tinha feito essa integração com Azure Data Factory, apenas via Python, mais isso não seria o problema, combinei com ele que estaria buscando entender como que poderia ser feito visto que pela documentação isso é permitido. E assim que concluísse, criaria um post para consultas futuras.
E você sabe como que funciona né, promessa é divida, bora pagar logo, simbora ao que interessa...
Vou explicar bem devagar, trouxe três casos onde:
Primeiro caso, explico um pouco do processo que realizo via Python. Nesse trabalho o primeiro passo antes de acessar os dados, é realizar um login. Para acessar essa URL, uso um usuário e senha, após a autenticação preciso capturar no header um token que é usado para acesso aos dados, resumido, faço a chamada de duas APIs;
Segundo caso, utilizo uma API pública do site https://openweathermap.org/. Esse disponibiliza de forma gratuita algumas APIs bem interessantes. Para nosso post, escolhi uma API que retornar informações do clima de uma determinada cidade do mundo. Primeiro apresento uma forma engessada para buscar os dados através de uma URL fixa;
Terceiro caso, uso a mesma API porém dessa vez parametrizando a chamada da na Pipeline fazendo a leitura de um arquivo JSON e buscar as informações de todas as cidades do mundo, em ambos os casos.
Para ambos os casos, os dados são gravados em nosso Azure Storage Account no Blob.
Caso fique alguma dúvida, peço que deixe um comentário.
Prontos? Podemos inicar? Eu ouvi SIM? Então tá, valendo!
Primeiro passo será realizar o login Azure Data Factory. Login realizado com sucesso, você será direcionado para a tela abaixo. Vamos analisar a imagem abaixo?
É uma velha conhecida, em nosso penúltimo post passamos por ela.
Bem simples, fique calmo, estamos juntos. Para dar o pontapé inicial, que tal seguir os passos a seguir? A hora é essa.
Vamos clicar no ícone da casinha (1) e em seguida, vamos clicar em Ingest (2). Acompanha comigo.

Feito isso, partiu próxima tela!
(1) Selecionar Built-in copy task;
(2) Selecionar Run once now (Processo é executado no final);
(3) Clicar em NEXT.

Na próxima tela vamos realizar a criação do conexão com a origem (Source).
Primeiro vamos configurar o Linked Service e em seguida o DataSet.
Configurando o Linked Service com o Source
Na tela abaixo vamos escolher o tipo da nossa origem.
(1) Selecione o tipo do dado da sua origem;
(2) Selecione a forma de conexão;
Obs: Caso exista mais de uma opção, uma lista será carregada conforme imagem abaixo.

Lembrando que esse passo inicia com a criação de um Linked Service, caso não exista, e em seguida a criação de um DataSet.
Em nosso exemplo de hoje, vamos estabelecer uma conexão entre uma API e o seu retorno estaremos gravando dentro do Blob.
Acompanha aqui como que fazemos isso.
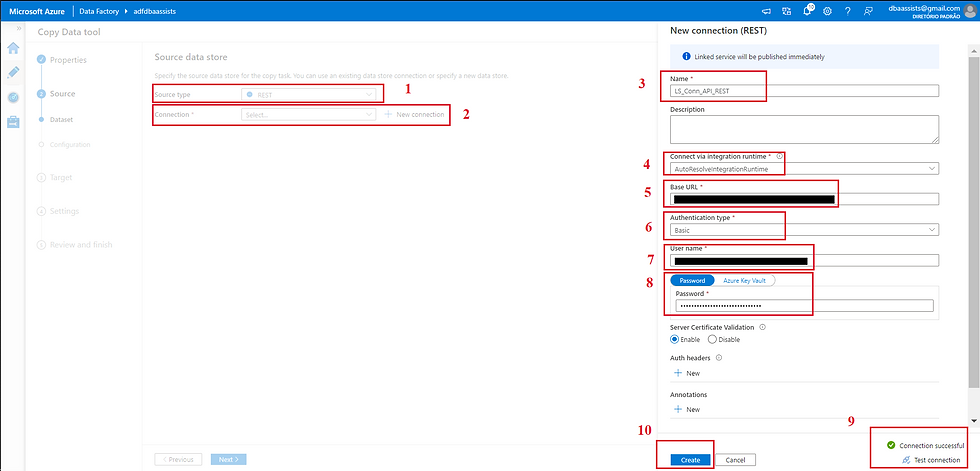
(1) Selecionar o tipo de origem (Source type) como REST;
(2) Clicar em New Connection;
(3) Informar um nome para o nosso Linked Service;
(4) Não vamos precisar informar uma IR pois estaremos trabalhando com dados de uma API;
(5) Informar o caminho da API (nesse exemplo vamos trabalhar com uma API que necessita um login para depois poder acessar os dados dela);
(6) Em Authentication type, vamos selecionar Basic;
(7) Informar um usuário da conta;
(8) Informar a senha da conta;
(9) Clicar em Test Connection para poder validar a conexão;
(10) Clicar em CREATE.
Conexão estabelecida, vamos avançar para o próximo passo.
Vamos nesse momento realizar a criação do nosso DataSet.
(1) Linked service criado;
(2) URL que será usada para autenticação na API;
(3) Relative URL, nesse passo vamos informar a nossa URL que contem os dados que vamos precisar (Podemos também clicar em Preview para analisar um breve retorno dos dados);
(4) Método de conexão usaremos o GET;
(5) Em Additional Header vamos passar o token que é retornado ao estabelecer uma conexão;
(6) Podemos também realizar a exportação via JSON ou gravar diretamente em uma collection do Cosmos (vamos ver mais a frente o que seria isso);
(7) Avançar clicando em NEXT.

Após concluir a configuração do Source, vamos para o Target, ou destino como queira falar.
Do mesmo modo que ocorre com o Source, ocorre como Target. O primeiro passo é sempre a criação de um Linked Service e em seguida o DataSet.
Como já possuímos um Linked Service criado que aponta para o nosso Blob, não existe a necessidade de realizar a criação de outro. No próximo post vou focar em criações de Linked Services, não percam!
(1) Conforme falado acima, vou usar um Linked Service já criado anteriormente;
(2) Definir onde será gravando no Blob**;
(3) Em file name vamos informar um nome para o nosso arquivo;
(4) E para avançar, clicar em NEXT.
** Conforme comentado em outro post, o diretório no blob em que os dados serão gravados, caso não exista, ele é criado no momento da execução.

No próximo passo vamos definir o formato do nosso arquivo.
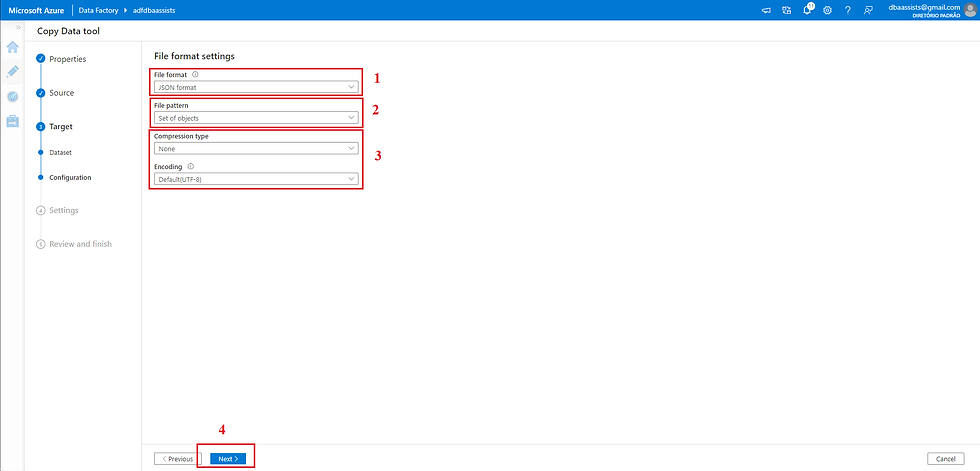
(1) Definir o file format, no nosso caso JSON format;
(2) File pattern, deixar default;
(3) Compression type, deixar o default;
(4) Para avançar vamos clicar NEXT;
Nesse passo podemos informar um nome para a nosso Pipeline e definir um log caso ocorra alguma falha.
Essa questão do log é bem usada principalmente quanto estamos trafegando dados para um banco de dados e caso venha a ocorrer algum erro de insert, conseguimos capturar e armazenar para uma análise futura.
(1) Definir um nome para a Pipeline ou manter o valor default, esse nome pode ser editado em outro momento mais a frente;
(2) Definir rotina de log;
(3) Para prosseguir basta clicar em NEXT.

Estamos chegando no término do processo de criação. Esse é o momento onde realizamos os ajustes finais. Onde colocamos a estrelinha, a purpurina, ajeitamos o nome das conexões, enfim, nada que mude as configurações realizadas anteriormente.
(1) Alterar o manter o nome da Pipeline;
(2) Alterar ou manter o nome do DataSet do Source;
(3) Alterar ou manter o nome do DataSet do Target;
(4) Alterar ou manter configurações de cópia;
(5) Caso esteja de acordo, basta clicar em NEXT.

Após clicar em NEXT na tela anterior, o Azure Data Factory realizará o deploy do pacote.
Esse deploy consiste na criação do Pipeline completo.

Deploy concluído, vamos clicar em FINISH e partir para execução.
Para execução, basta clicar no botão DEBUG.

Agora saímos do Azure Data Factory e vamos acessar nossa conta do Azure.
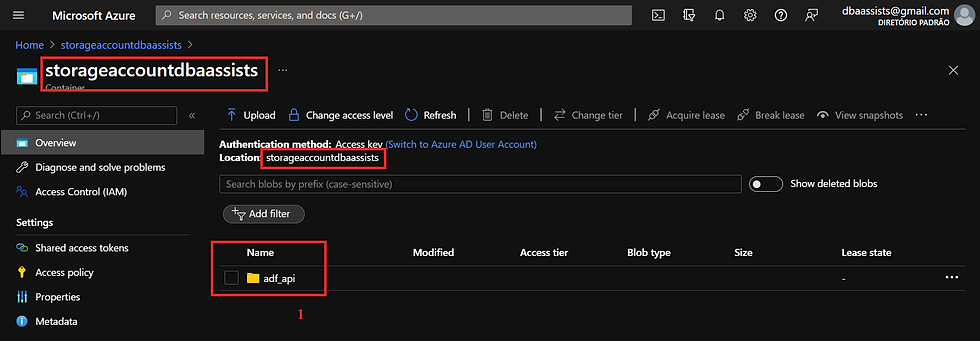
Após acessar, vamos navegar na nossa Azure Storage Account até chegar ao local que definimos como o Target do nosso fluxo.
(1) Target - storageaccountdbaassists/adf_api
Descendo um nível no nosso diretório, chegamos até o arquivo gerado.
Muito bem primeira parte concluída. E ai o que achou até o momento? Fácil, médio ou difícil? Responde ai...pode colocar sua dúvida nos comentários.
Vamos avançar para o próximo.

Vamos para o nosso segundo caso...
Busquei na internet alguma API grátis para esse nosso próximo passo.
Após algumas buscas, encontrei o site OpenWeather. Achei um site super bacana, nele conseguimos acessar muitas informações referente ao cima de diversas cidades do mundo.
Uma excelente fonte de dados para o nosso exemplo! Acompanha comigo.
Primeira ação que você vai precisar fazer é a criação de uma conta. É totalmente grátis, pode ficar tranquilo.
Isso se faz necessário, pois quando formos chamar a API existe a necessidade de informar a sua API Key. Vamos lá, acessa ai e cria a sua conta.

Conta criada e login realizado, vamos navegar por Current Weather Data, basta clicar em API doc.

Após acessar a tela API doc, é possível observar a quantidade de possibilidades de busca da mesma informação.
É possível buscar por nome de cidade, pelo código da cidade (vou mostra mais a frente como conseguir o código das cidades), por coordenadas geográficas (Lat e Long), por código postal e outras.
Além disso, ele coloca um exemplo de cada chamada, quer coisa mais fácil?
Buscar por Nome:
api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}Buscar por Código de Cidade:
api.openweathermap.org/data/2.5/weather?id={city id}&appid={API key}Buscar por Coordenadas Geográficas:
api.openweathermap.org/data/2.5/weather?lat={lat}&lon={lon}&appid={API key}Como repararam, em todas as chamadas existe a necessidade de informar a sua API Key. Vamos observar como que encontramos. É bem simples chegar nela.
(1) Clicar em My API keys

Na tela abaixo basta copiar a sua API Key.
(1) Copiar API Key

Agora vamos dar um passo atrás e voltar ao ponto onde comentei que é possível fazer a busca através de várias opções.
O primeiro passo é realizar o download do catálogo de cidades.
Conforme imagem abaixo, vamos procurar por Bulk Downloading e após isso clicar am API doc.

Feito isso, seremos direcionado para a página ilustrada na imagem a seguir.
Vamos navegar até o link da tela abaixo.

Ao clicar no link, você será direcionado para a próxima tela.
Nela, vamos realizar o download do arquivo com todas as informações.
(1) Clicar no link para realizar o download do arquivo.
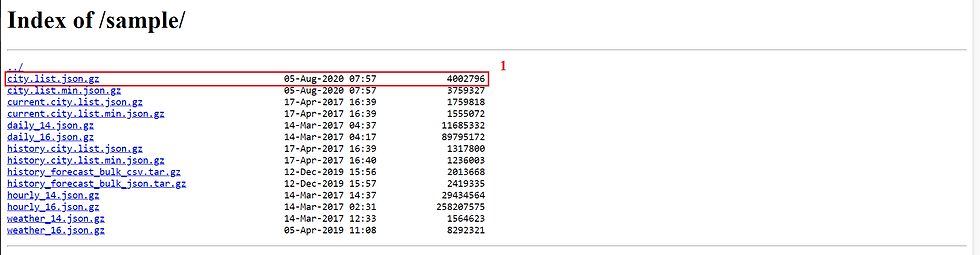
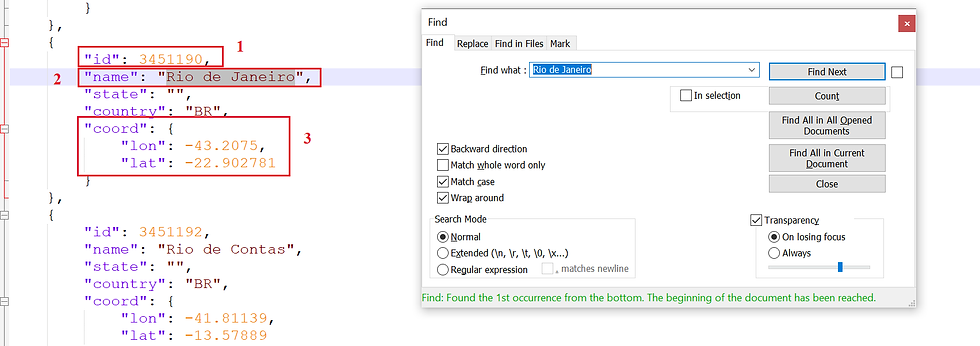
Na imagem abaixo (um print do json da tela anterior) conseguimos identificar algumas informações:
(1) Código da Cidade (id);
(2) Nome da Cidade (name);
(3) Coordenadas geográficas (coord).
Pois bem meu amigo, até aqui falamos da nossa API, expliquei como podemos buscar as informações. Agora vamos iniciar a criação da nossa Pipeline.
Acompanha aqui comigo!
(1) Vamos criar uma Pipeline e irei nomear ela para PIP_EXTRAI_DADOS_API.

Na próxima tela, vou colocar um componente de Copy Data. Esse componente será o responsável por realizar a conexão com a origem (API) e o destino (Blob).
(1) Clicar em Copy Data;
(2) Clicar no componente no centro da tela;
(3) Clicar sobre o componente e na aba inferior renomear para um nome que deixe claro o seu objetivo.

Agora, nessa tela, vamos realizar a criação do mecanismo de conexão com o a origem.
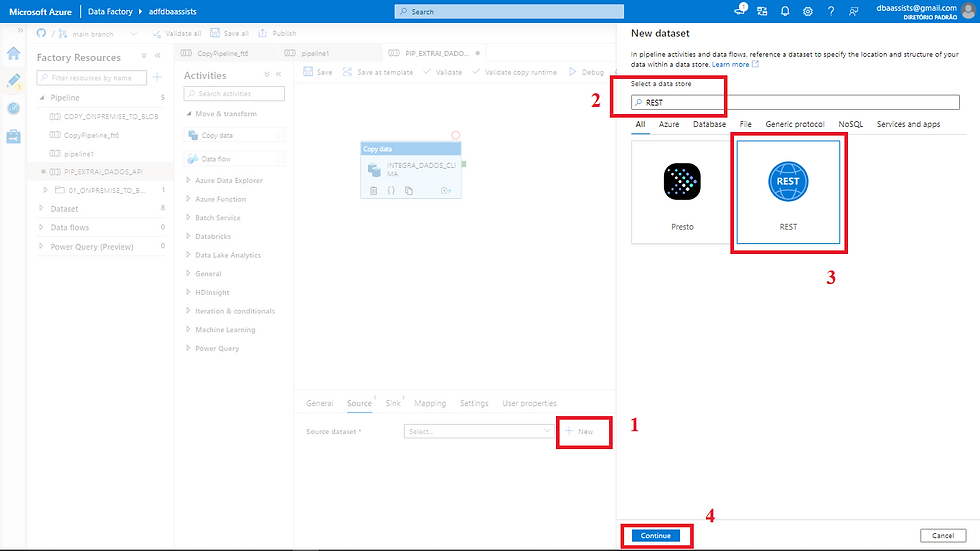
(1) Após clicar em Source, em Source DataSet, vamos clicar em New;
(2) Ao clicar em New a tela lateral será carrega. Na barra de busca vamos digitar REST;
(3) Busca concluída, vamos clicar em REST;
(4) Para avançar para a próxima tela, clicar em CONTINUE.
Nosso primeiro passo será a criação de um Linked Service (caso já tenha um configurado pode estar utilizando);
(1) Informar um nome para o Linked Service;
(2) Clicar em New para criação.

Ao clicar em New, a tela abaixo é apresentada. Vamos as orientações.

(1) Informar um nome para o Linked Service;
(2) Não vamos alterar a configuração da IR pois não vamos usar;
(3) Em Base URL, informar o link da API;
(4) Em Authentication type escolher Anonymous;
(5) Clicar em Test Connection para validar a criação;
(6) Teste realizado com sucesso, clicar em CREATE.
Conforme falamos acima, a chamada de qualquer uma das nossas APIs de exemplo, requer a passagem de pelo menos dois parâmetros.
Após realizar a criação do DataSet, vamos realizar a parametrização da URL.
(1) Selecionar o DataSet;
(2) Clicar na aba Parameters.

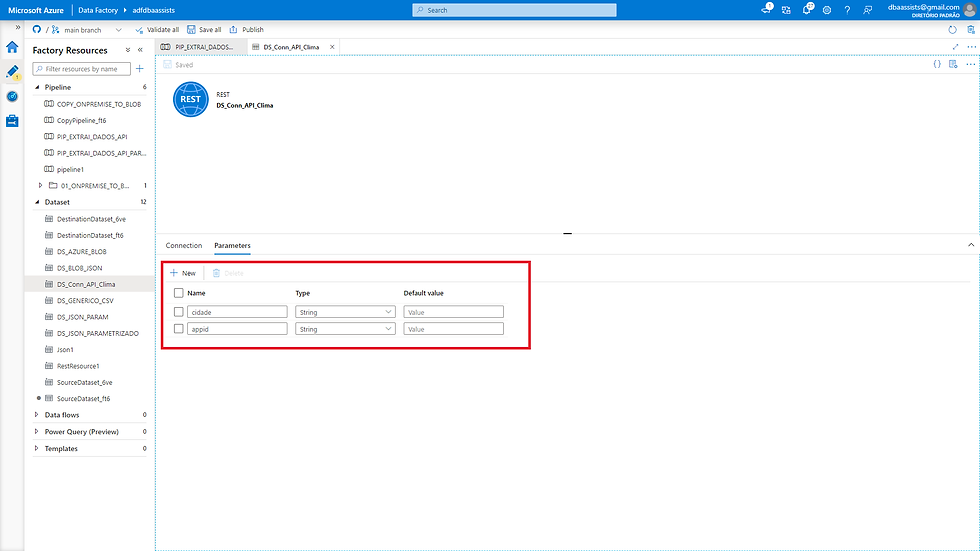
Na tela abaixo, vamos criar dois parâmetros.
(1) cidade, tipo string;
(2) appid, tipo string.
Após a criação dos parâmetros, vamos salvar e fechar a tela do DataSet.
Feito isso, seremos direcionado para a tela abaixo.
Observem que os dois parâmetros criados, agora são apresentados. Vamos realizar a parametrização deles.
(1) Ao clicamos sobre o campo, uma opção abaixo do campo é habilitada Add dynamic content, vamos clicar no link;
(2) Informar London,uk;
(3) Clicar em OK.

Vamos repetir a mesma operação, porém agora vamos configurar o appid.
(1) Ao clicamos sobre o campo, uma opção abaixo do campo é habilitada Add dynamic content, vamos clicar no link;
(2) Informar 7bc2cc7213df7f6dad3df7288fb4ee36;
(3) Clicar em OK.

Configuração concluída, vamos ver como que ficou.
(1) Componente criado;
(2) Dataset criado;
(3) Parâmetros configurados.

Para avança na próxima tela, vamos clicar no botão Open. Ele fica ao lado do nome do nosso DataSet.
Essa ação nos levou até a tela de configuração do nosso DataSet.
Nesse ponto vamos realizar a parametrização da chamada da nossa API.
Ai veio aquela pergunta, pra que isso?
A resposta é bem simples. Agora na sua execução você está buscando informações de Londres e se mais tarde você quiser buscar a informação do Rio de Janeiro, vai criar outro DataSet? Claro que não, basta alterar o nome no parâmetro que criamos. Viu como que é simples?
Agora partiu configuração da chamada da API.
(1) Em Relative URL, vamos clicar em Add dynamic content;
(2) Na tela que será aberta a direita, vamos realizar a concatenação de valores para monta a URL, observe como que fica.
Observe que misturamos tudo, URL e variável. kkkkk
(3) Concluído, basta clicar em OK

Será que funcionou? Vamos verificar...segue comigo aqui...
(1) Clicar em Preview Data;
(2) Parâmetros informados;
(3) Visualizar uma amostra dos dados.

Vamos configurar agora nosso Target.
(1) Após clicar em Sink, em Sink Dataset, vamos clicar em New;
(2) Ao clicar em New a tela lateral será carrega. Na barra de busca vamos digitar Azure Bob;
(3) Busca concluída, vamos clicar em Azure Blob Storage;
(4) Para avançar para a próxima tela, clicar em CONTINUE.

Como vamos utilizar um Linked Service existente, vamos apenas nomear nosso DataSet e escolher o Linked Service na lista.
(1) Informar nome para o DataSet;
(2) Listar os Linked Services criados;
(3) Selecionar o Linked Service.

Ao selecionar o Linked Service, os campos referentes aos passos 3, 4 e 5 são habilitados.
Nesse momento, o passo 3 não iremos preencher, vamos clicar no passo 4 e a próxima tela será carregada.

Nessa tela, vamos preencher as seguintes informações.
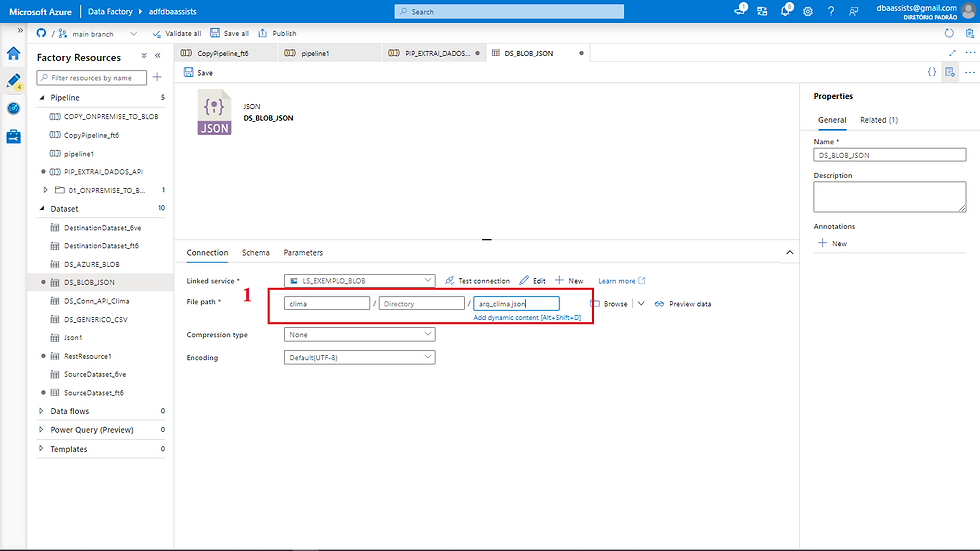
(1) Em container, vamos digita clima, onde clima será o diretório que vai ser criado em nosso Blob.
(1) Em file, vamos definir o nome do arquivo que será criado quando a Pipeline for executada, em nosso exemplo, defini o nome do arquivo como arq_clima.json.
Feito isso vamos clicar em Save para confirmar as informações.
Agora com o Source e Target configurados, vamos executar nosso Pipeline e verificar se vai funcionar ou não.
(1) Na imagem abaixo, apresento o detalhe da sua execução.

Concluímos aqui o processo de criação da nossa Pipeline consumindo uma API.
Vamos agora sair do nível intermediário para o nível avançado.
Mais o que seria esse nível avançado? Vocês lembram daquele arquivo gigante com as cidades? Pois bem, vamos criar um novo Pipeline que fará a leitura desse arquivo, vai fazer a chamada da API para cada cidade e do mesmo modo vai gravar um arquivo no Blob para cada cidade.
Vamos ver como que faz isso.
E agora vamos para o nosso terceiro caso!
Conectando com uma API parametrizando o Azure Data Factory
Conforme mencionado acima, vamos criar um fluxo agora no Azure Data Factory que fará uma leitura de um arquivo, e irá passar um registro por vez para um fluxo de loop.
Acompanha aqui, não perde o foco!!
Para iniciar os trabalhos, vamos acessar nossa conta do Azure, depois nosso Azure Storage Account e carregar o nosso arquivo com as informações das cidades.
(1) Diretório Criado;
(2) Arquivo com as cidades.

No segundo passo, vamos criar nossa Pipeline. Vou nomear a nossa Pipeline de PIP_EXTRAI_DADOS_API_PARAMETRIZADO, após isso, em Activities selecionar em General o componente Lookup.
Ao clicarmos sobre o componente, ele será projeto na tela de centro da nossa tela.
(1) Selecionar o componente Lookup;
(2) Informar um nome para o componente;
(3) Definir um Linked Service para acessar o nosso arquivo de cidades;
(4) Clicar em Open this dataset;

Após clicar em Open this dataset, você será redirecionado para a tela abaixo.
Nesta tela vamos clicar em Parameters e seguir para a próxima tela.

Nessa tela vamos criar os parâmetros para utilização em nosso componente de lookup.
(1) Aba onde criamos os parâmetros;
(2) Vamos criar dois parâmetros:
container - diretório no blob
arq_param - nome do arquivo que contém as informações

Após a criação dos parâmetros, vamos retornar a aba Connection.
(1) Vamos configurar o container (diretório) e o file (arquivo de dados).
Na tela abaixo, observamos como parametrizar o caminho do container.
(1) Em container vamos clicar em Add dynamic content;
(2) Clicar sobre o parâmetro (Parameters) container;
(3) E automaticamente ele será carregado;
(4) Clicar em OK.

Na tela abaixo, observamos como parametrizar o caminho do arquivo.
(1) Em file vamos clicar em Add dynamic content;
(2) Clicar sobre o parâmetro (Parameters) arq_param;
(3) E automaticamente ele será carregado.
(4) Clicar em OK.
Para encerrar basta clicar em Save.

Primeira configuração concluída. Observe a tela abaixo.

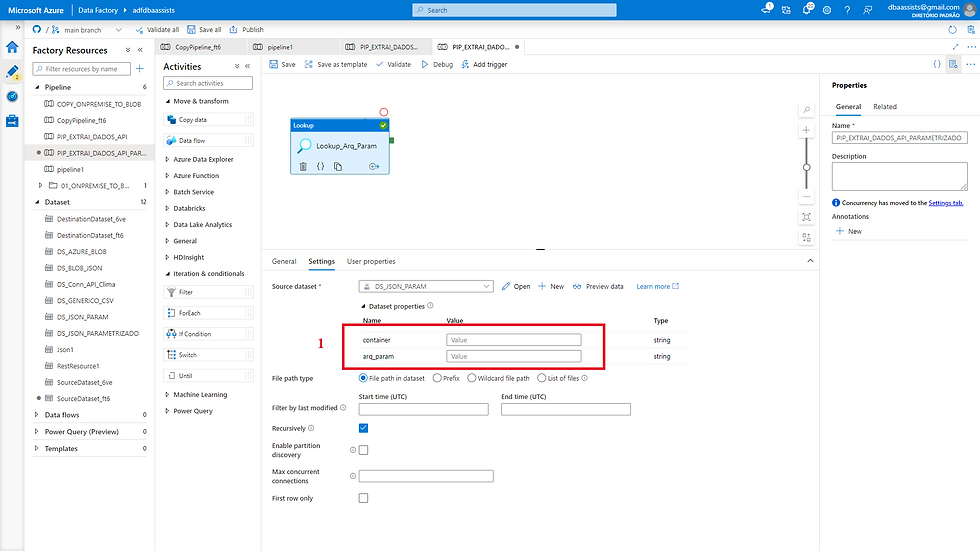
Após a configuração do Linked Service, do DataSet, da criação dos parâmetros, chegou o momento de informar os valores. Observe abaixo.
(1) Devemos informar o container (diretório no blob) e o nome do arquivo que contém as informações necessárias para busca das informações via API.
A configuração é bem semelhante com as que fizemos anteriomente.
(1) Em container vamos clicar em Add dynamic content;
(2) Digitar parametro;
(3) Clicar em OK.

(1) Em arq_param vamos clicar em Add dynamic content;
(2) Digitar city.list.json
(3) Clicar em OK.

Vamos executar a Pipeline para validar a configuração realizada.

Executado com sucesso, vamos criar nosso componente de ForEach, esse componente será responsável por realizar o loop com os dados do arquivo.
Em Activities, vamos navegar em Iteration & conditionals e em seguida ForEach.
Ao clicarmos em ForEach, o objeto (1) da imagem abaixo é carregado.
Vamos iniciar a sua configuração.
Na aba General, em name vamos dar um nome para identificar nosso objeto no fluxo.

Após informar um nome, vamos para a aba Settings, em Items, vamos configurar a chamada para a iteração com os dados do arquivo que é lido no Lookup.

Essa configuração pode ser feita da seguinte forma:
(1) Na aba Settings;
(2) Em Items, clicar em Add dynamic content;
(3) Ao clicar em Add dynamic content, a aba da direita é aberta e para inserir o valor vamos clicar em Lookup_Arq_Param;
(4) Ao clicar o valor @activity('Lookup_Arq_Param').output vamos complementar com ".value";
(5) Clicar em OK.

No passo seguinte vamos realizar a configuração do nosso fluxo de integração entre a API e o Blob.
(1) Clicar na aba Activities;
(2) Clicar no lápis ao lado de Activities.
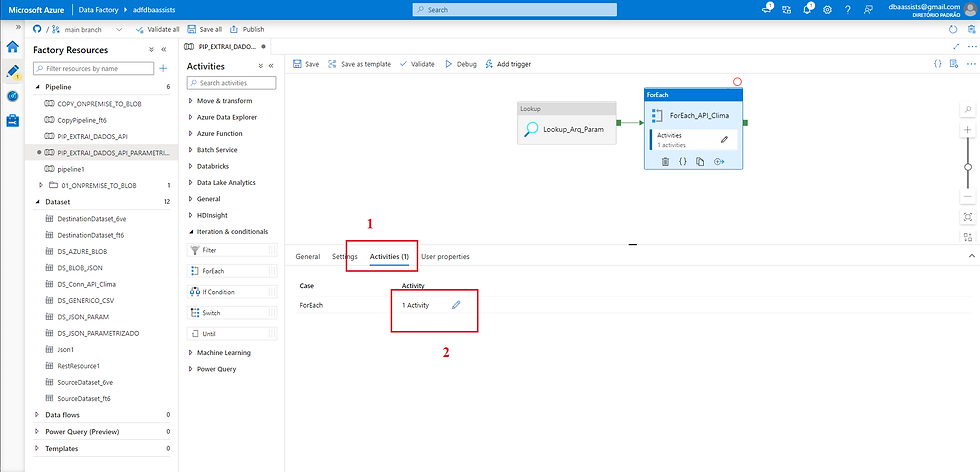
A tela abaixo é carregada quando clicamos no passo anterior no lápis.
Nessa tela, vamos clicar no componente Copy Data e ele será carregado no meio da tela.
Vamos fazer a configuração.

Vamos ver a configuração da tela abaixo.
(1) Em cidade vamos clicar em Add dynamic content;
(2) Na tela que é carregada a direita vamos concatenar as informações de seguinte forma: cidade, país, veja como que fica.
@{concat(concat(item().name,','),item().country)}
(3) Clica em OK.

Mesma coisa para o campo appid.
(1) Em appid vamos clicar em Add dynamic content;
(2) Na tela que é carregada a direita você vai informar o seu API Key;
(3) Clica em OK.

Source configurado, agora vamos configurar o Sink (destino).
(1) Vamos clicar na aba Parameters para criar nossos parâmetros, acompanhe na próxima tela.

Em Parameters vamos criar duas entradas.
(1) Os parâmetros que iremos criar serão container e arquivo.

Parâmetros criados, vamos retornar a aba Connection.
(1) Em container, vamos clicar em Add dynamic content;
(2) Ao clicar uma tela a direita será aberta, nessa tela vamos clicar em container (Parameters);
(3) O valor ser apresentado no topo da tela;
(4) Clicar em OK.

Do mesmo modo, vamos configura a entrada referente ao nome do arquivo.
(1) Em file, vamos clicar em Add dynamic content;
(2) Ao clicar uma tela a direita será aberta, nessa tela vamos clicar em arquivo (Parameters);
(3) O valor ser apresentado no topo da tela;
(4) Clicar em OK.
Concluída a configuração, basta clicar em salva e fechar a tela do DataSet.

Retornando para o componente Copy Data, vamos parametrizar agora a entrada das informações.
Vamos começar configurando a variável container.
(1) Em container vamos clicar em Add dynamic content;
(2) Na tela que irá abrir a direita você irá digitar clima;
(3) Clicar em OK.

Da mesma forma, vamos configurar a variável arquivo.
(1) Em arquivo vamos clicar em Add dynamic content;
(2) Na tela que irá abrir a direita vamos concatenar o nome do arquivo, o nome da cidade, o nome do país e a extensão do arquivo. Ficando da seguinte forma:
@{concat(concat(concat(concat('arq_clima_',item().name),'_'),item().country),'.json')};
(3) Clicar em OK.

Vamos analisar o nosso diretório de destino no Blob.

Após a execução da nossa Pipeline alguns arquivos já foram carregados.
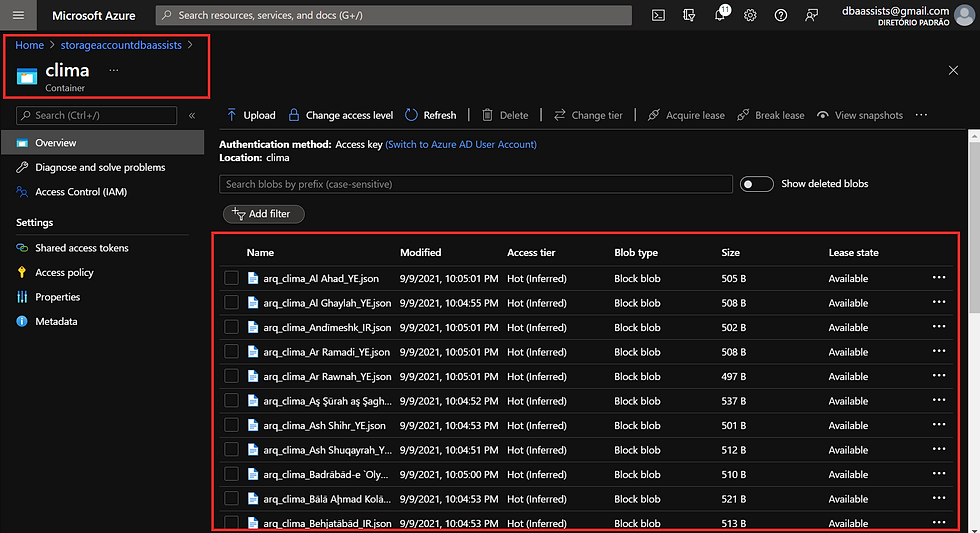
Analisando essa imagem conseguimos verificar que 1465 arquivos foram criados até esse momento.

Conclusão
Pois bem meu amigo, chegamos aqui no término de mais um post. Ufa esse foi grande, mais foi bacana demais! Aprender algo novo é sensacional.
Espero que tenha conseguido trazer para você a ideia de como podemos conectar o Azure Data Factory a uma API e salvar o seu retorno em um blob.
Espero que tenha gostado do assunto, eu confesso que nunca tinha conectado o Azure Data Factory em uma API, sempre fiz esse trabalho via Python.
Pra mim agregou bastante valor espero que você tenha conseguido alcançar o mesmo resultado.
Espero você no próximo, grande abraço e fique com Deus.
Comentarios