
E ai meu amigo tudo bem?
Hoje trago para você um recurso muito útil que existe no Azure Data Factory. Quem já trabalhou ou trabalha com o Microsoft SQL Server, provavelmente já fez uso de um recurso muito bom para cópia de dados entre ambientes.
Esse recurso é chamado de Import and Export Wizard. Conforme o seu nome, sua finalizada é importar e exportar dados de um lugar para o outro, assim mesmo, sem tirar nem pôr! Podemos usar para copiar dados entre bancos de dados, exportar dados de um banco de dados para um arquivo, ou seja, possuí mil e uma utilidades.
O Azure Data Factory também possuí o seu Import and Export, porém ele recebe o nome de Copy Data Tool e muitos não conhecem, eu era um deles! Imagina se para cada tabela que você precisasse exportar de um banco e importar em outro você tivesse que realizar toda a configuração de Copy data, criação de Dataset, no fim da contas você perderia muito tempo fazendo uma atividade rápida e simples. Por muitas vezes desisti de fazer no Azure Data Factory e optei por fazer via Microsoft SQL Server.
Mais fica tranquilo, isso é uma atividade muito simples! Vou explicar timtim por timtim para você. Porém antes de entrar no assunto, vou explicar para quem não conhece como que funciona o nosso querido Import and Export Wizard.
Segue aqui comigo...
1 - Import and Export Wizard
Pois bem meu amado, primeiro passo para pode acessar o Import and Export Wizard é realizar o login no seu Microsoft SQL Server. Feito isso vamos seguir os seguintes passos.
(1) Clicar com botão direito sobre o seu banco de dados, não necessariamente precisa ser o banco de origem ou destino, essa escolha será feita mais a frente;
(2) Após clicar, navegar até Tasks, caso seu Client do Microsoft SQL Server esteja em português, sua opção será Tarefas;
(3) Selecionar Import Data (em português será Importar Dados), para importar ou Export Data (em português será Exportar Dados) para exportar.
Concluída a seleção, vamos para a próxima tela.


Nada muito a explicar nessa tela, vamos clicar em Next para avançar...
Observe que existe uma opção para impedir que essa tela seja carregada sempre que você selecionar o recurso.
Para isso basta marcar Do not show this stating page again.
Bora caminhar...
Para esse nosso exemplo, estaremos usando como Source e Destination o Microsoft SQL Server, lembrando que o Import and Export Wizard pode ser usado em vários recursos.
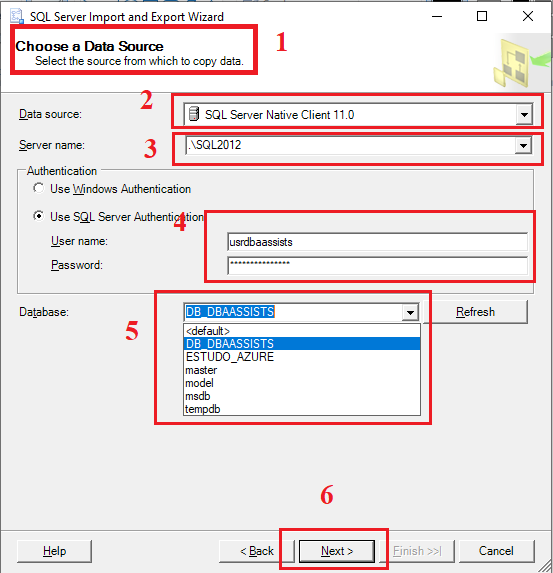
Nessa próxima tela, vamos fazer a configuração de acesso da nossa origem (Source).
(1) Informação de que estamos configurando o Source;
(2) Nesse passo você escolhe o tipo do seu Data Source, em nosso exemplo, vamos selecionar SQL Server Native Client 11.0;
(3) Informar qual o servidor\instância;
(4) Informar qual o usuário e senha caso tenha escolhido a opção de Autenticação Use SQL Server Authentication;
(5) Selecionar qual o banco de dados;
(6) Clicar em Next para avançar.
Agora vamos avançar para configurar o nosso destino (Destination ou Target).
Os passo são exatamente os mesmos que realizamos no Source.

(1) Informação de que estamos configurando o Destination;
(2) Nesse passo você escolhe o tipo do seu Data Source, em nosso exemplo, vamos selecionar SQL Server Native Client 11.0;
(3) Informar qual o servidor\instância;
(4) Informar qual o usuário e senha caso tenha escolhido a opção de Autenticação Use SQL Server Authentication;
(5) Selecionar qual o banco de dados;
(6) Clicar em Next para avançar.
Origem (Source) e Destino (Destination ou Target) configurados, agora vamos selecionar o que pretendemos copiar.
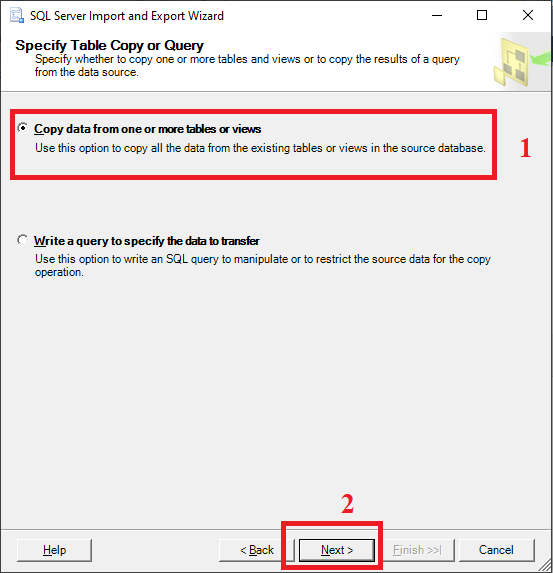
Nesse passo possuímos duas opções:
Copy data from one or more tables or views ou Write a query to specify the data to transfer, ou seja, na primeira opção você seleciona as tabelas e na segunda você escreve a query.
(1) Vamos marcar a primeira opção;
(2) Clicar em Next para avançar.
Pronto, vamos selecionar agora as tabelas da origem e para onde os dados devem prosseguir.

(1) Nesse exemplo, vamos selecionar todas as tabelas;
(2) Sempre que esse ícone aparecer, indicar que a tabela não existe no destino;
(3) Clicando na opção é possível visualizar a estrutura da tabela, o mapeamento dos campos e outras informas. Vamos abordar com mais detalhes na próxima tela;
(4) Vamos clicar em Next para seguir.
Quando clicamos na opção Edit Mappings, a tela abaixo é apresentada. Vamos detalhar as opções.
(1.1) É possível verificar e alterar o script de criação da tabela. Essa opção está habilitada apenas porque essa tabela não existe no destino, verificar item (2);
(1.2) O script propriamente dito, podemos altera-lo caso seja necessário;
(1.3) Mapeamento do dos campos, com datatype, nulabilidade (se o campo aceita valores nulos ou não);
(2) Como a tabela não existe, essa opção não é possível ser alterada;
(3) Essa opção quando informada, toda vez que o processo de Import and Export é executado, a tabela é eliminada (Drop Table) e recriada (Create Table);
(4) Caso exista alguma coluna identity no destino, o valor da origem é preservado;
(5) Clicar em OK para seguir.

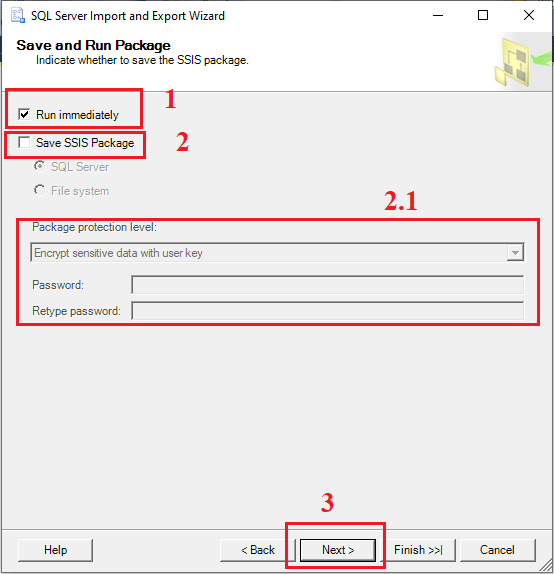
Tudo pronto, agora vamos definir o gran finale.
(1) Essa opção marcada define que o processo deverá ser executado imediatamente;
(2) Essa opção permite que o pacote seja salvo em disco ou até mesmo no Microsoft SQL Server Agent;
(2.1) Ao marcar a opção do item (2), algumas informações serão habilitadas para preenchimento;
(3) Clicar em Next para prosseguir.

Essa próxima tela apresenta um resumo do que será feito.
(1) Qual é a origem e qual é o destino;
(2) O que será copiado e onde será copiado;
(3) Informações referente a execução do pacote, se ele será salvo, se será executado imediatamente;
(4) Clicar em Finish para concluir.

Todo executado conforme esperado. Parabéns jovem gafanhoto.
(1) Resumo geral do que foi feito;
(2) Quantidade de registros copiados;
(3) Clicar em Close para finalizar tudo.
Caso seu pacote tivesse sido executado com falha, o Import and Export Wizard fornece a opção de voltar nas configurações, resolver o problema e reexecutar tudo, em caso de sucesso, vale o que você definiu em relação apenas a execução ou se o pacote será salvo.
Caso tenha assinalado apenas a sua execução, posso dizer que o seu pacote é auto destruído no final e caso tenha optado por salva-lo, ele estará lindo e serelepe esperando você ré executa-lo.
Bem meu amigo, esse é o nosso processo usando o Import and Export Wizard do Microsoft SQL Server. Abordei apenas a cópia de dados entre dois bancos de dados. Porém o seu uso é mais abrangente, não fica resumido apenas nisso. Deixo abaixo um link da Microsoft para você navegar caso tenha algum interesse em saber maiores detalhes.

Microsft Import and Export Wizard - https://docs.microsoft.com/pt-br/sql/integration-services/import-export-data/start-the-sql-server-import-and-export-wizard?view=sql-server-ver15
2 - Azure Data Factory - Capy Data Tool
Agora vamos abordar esse mesmo recurso no no Azure Data Factory.
É um pouco diferente, mais lá na frente você vai falar que é igual. Quer apostar?

Acompanha comigo!
Primeiro passo será acessar o Azure Data Factory, clica aqui!
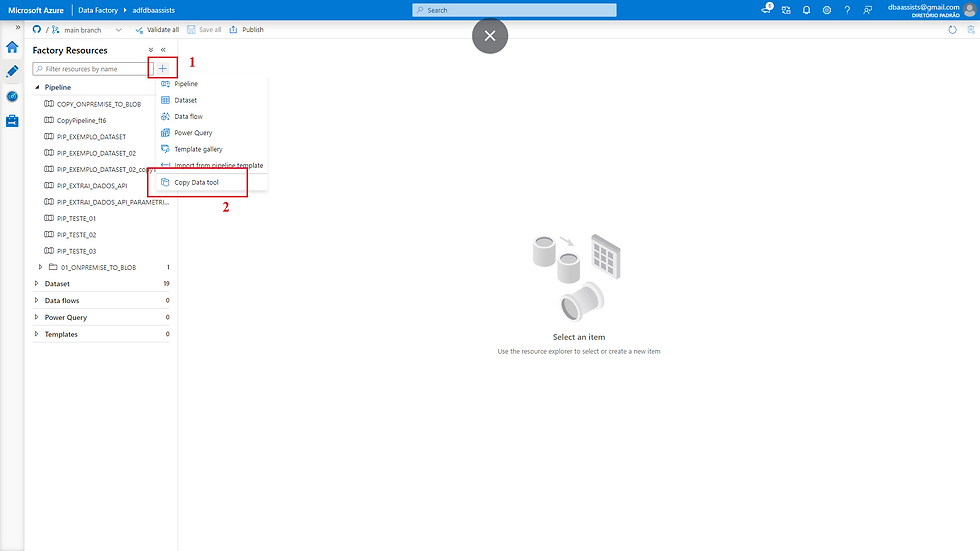
Acesso realizado com sucesso, vamos para a aba Author, basta clicar no ícone do lápis do lado esquerdo.
(1) Clicar no botão +;
(2) Selecionar Copy Data Tool.
Nessa tela vamos seguir os passo a seguir.
(1) Selecionar Built-in copy task;
(2) Deixar marcada a primeira opção Run only now.
Nessa opção pode existe a possibilidade de criar um agendamento para execução da nossa Pipeline. Essa opção também existe no Import and Export quando selecionamos ele para ser salvo e escolhemos a opção SQL Server.

Nessa tela vamos começar a configuração do Source.
(1) Indica que estamos configurando o Source;
(2) Selecionar o tipo do conector da origem (Source type);
(3) Selecionar o SQL Server pois estaremos trabalhando com o Microsoft SQL Server On Premise;
(4) Clicar em Next para avançar;
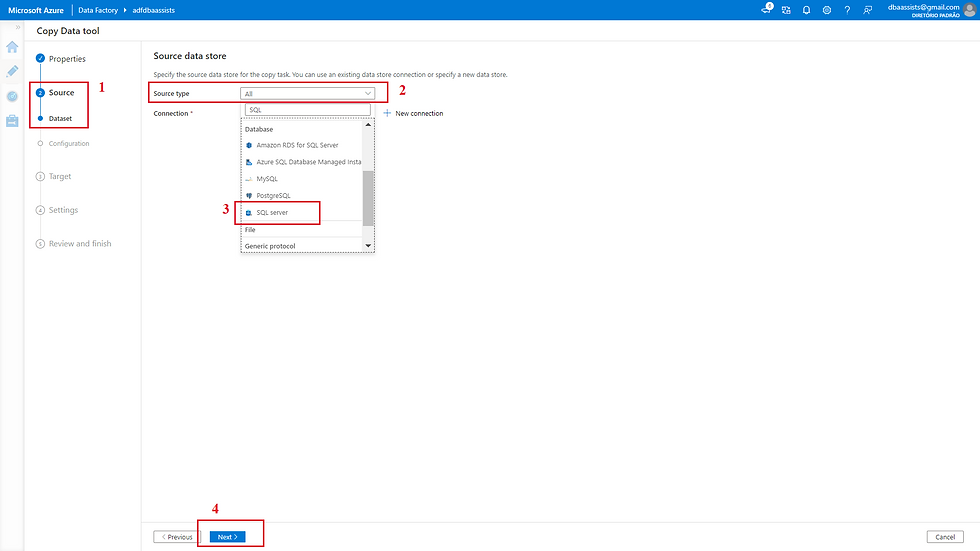
Na próxima tela vamos selecionar nosso Linked Service.
(1) Indica que estamos configurando o Source;
(2) Tipo do Source SQL Server selecionado;
(3) Selecionar o Linked Service criado em um post anterior;
(4) Informações do Linked Service (IR, nome do servidor, nome do banco de dados, etc);
(5) Clicar em Next para avançar.
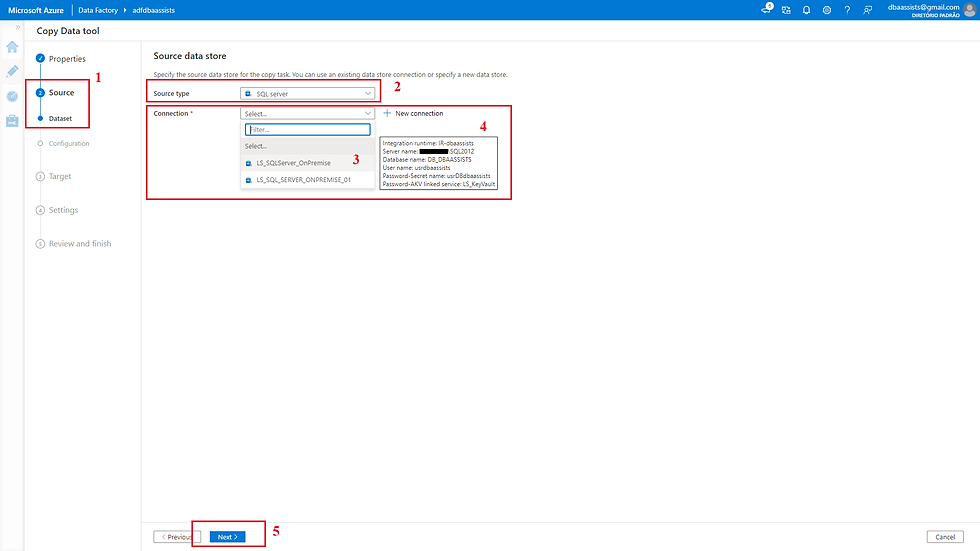
Após selecionar o Linked Service, as tabelas que existe no Source serão listadas para serem selecionadas.
(1) Indica que estamos configurando o Source;
(2) Tipo do Source SQL Server selecionado;
(3) Linked Service selecionado anteriormente;
(4) De modo semelhante ao Import and Export existe a possibilidade de selecionar as tabelas (Existing tables) ou escrever uma query (Use query);
(5) Listagem das tabelas que iremos carregar;
(6) Clicando em um desses ícones é possível visualizar os existentes na tabela;
(7) Clicar em Next para prosseguir.
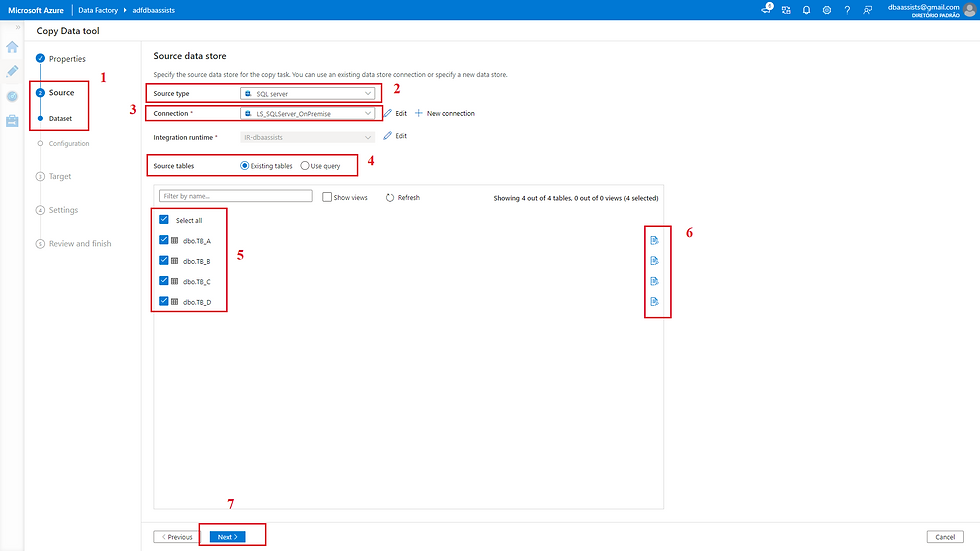
Nessa próxima tela, apresento os dados ao clicar no ícone da tela anterior, item (6).
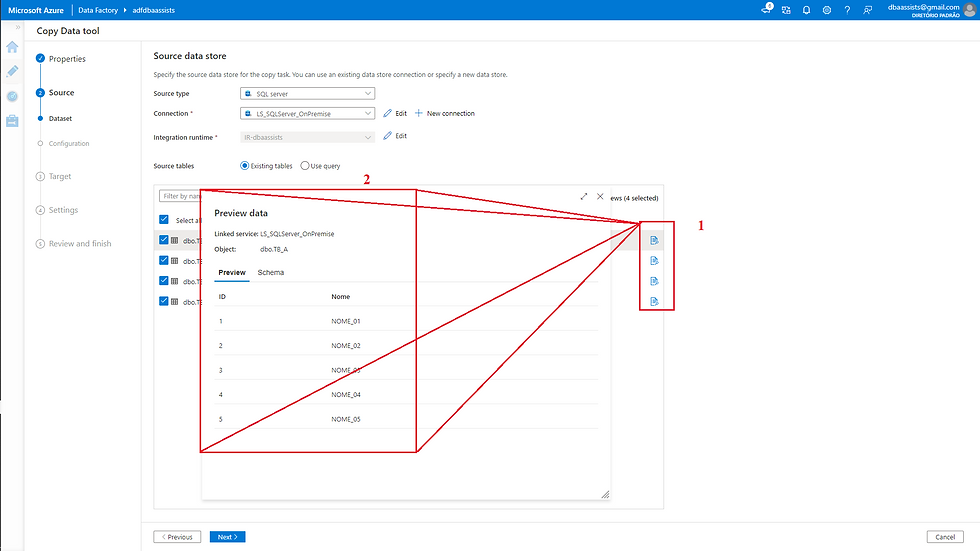
Na próxima tela
(1) Indica que estamos configurando o Source;
(2) Tipo do Source SQL Server selecionado;
(3) Linked Service selecionado anteriormente;
(4) Para acessar as tabelas (Source tables), vamos selecionar Use Query;
(5) Escrever um comando Select qualquer para listar os dados;
(6) Clicar em Preview Data para visualizar uma prévia dos dados da tabela;
(7) Dados apresentados;
(8) Clicar em Next para avançar.

Na próxima tela conseguimos visualizar alguns parâmetros que podem ser aplicados para o processo de carga.
(1) Aba de configuração;
(2) Listagem das tabelas;
(3) Configurações que são apresentadas como opção (Timeout, Isolation Level e Partition Option);
(4) Clicar em Preview Data para para visualizar os dados.

Vamos nesse momento fazer a configuração do nosso Destination.
(1) Indica que estamos configurando o Destination (Target);
(2) Tipo do Source SQL Server selecionado;
(3) Vamos selecionar um Linked Service que já possuímos;
(4) Clicar em Next para avançar.

A próxima tela é apenas uma apresentação de como que ficou nossa configuração.
(1) Indica que estamos configurando o Destination (Target);
(2) Configuração de conexão;
(3) Clicar em Next para avançar.

Agora vou apresentar como que realizamos a configuração do Destination (Target).
(1) Indica que estamos configurando o Destination (Target);
(2) Tipo do Source SQL Server selecionado;
(3) Linked Service selecionado anteriormente;
(4) Listagem das tabelas;
(5) Local onde realizamos configurações do destino;
(6) Nessa opção, podemos selecionar tabelas em nosso destino, para isso basta marcar e a após isso uma combo box é apresentada;
(7) Indica que caso não seja alterada a opção do item (6), essa tabela será criada no destino;
(8) Clicar em Next para avançar.
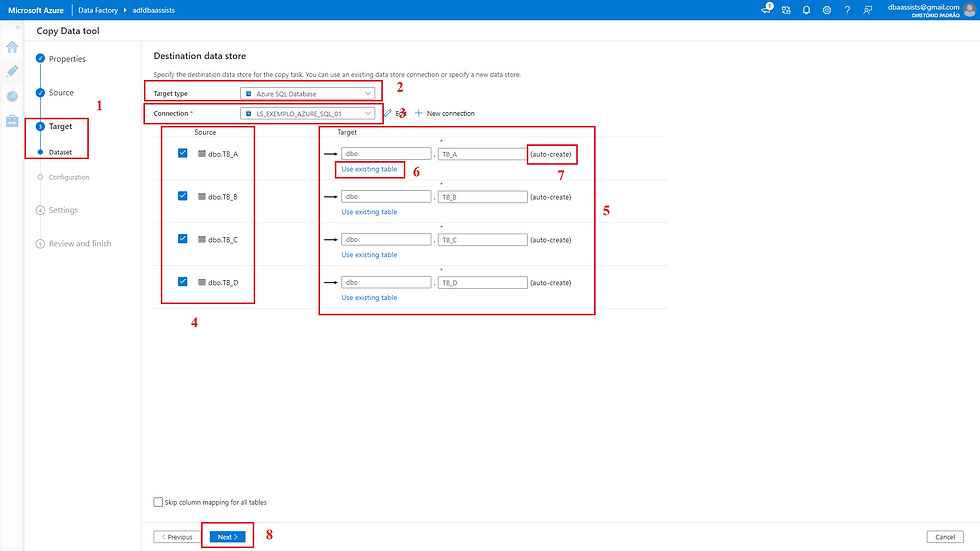
Na próxima tela apresento para você como que faríamos se as tabelas estivessem criadas no destino. Segue ai...
(1) Indica que estamos configurando o Destination (Target);
(2) Configuração de conexão;
(3) Listagem das tabelas;
(3.1) Opção de selecionar as tabelas. Essa opção é a que foi mencionada na tela anterior do item (6);
(3.1) Esse item tem o comportamento contrário do passo anterior. Ele permite que você alterne entre o modo de criação de tabela e seleção;
(4) Clicar em Next para avançar.

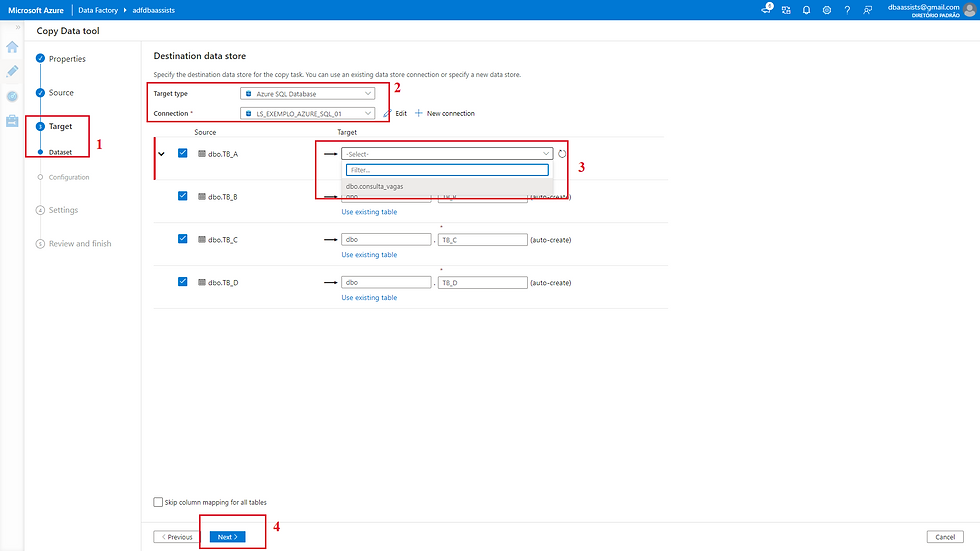
Uma breve apresentação do processo de seleção de tabelas.
(1) Indica que estamos configurando o Destination (Target);
(2) Configuração de conexão;
(3) Listagem das tabelas;
(4) Clicar em Next para avançar.
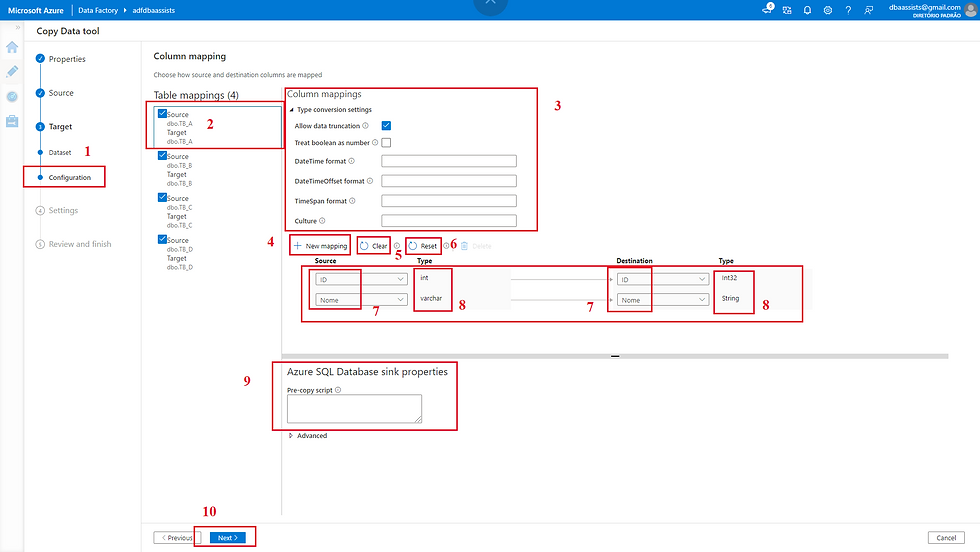
Essa tela possui um pouco mais de informações. Vamos bem devagar pra você não perder nenhum detalhe...
(1) Indica que estamos configurando o Destination (Target);
(2) Vamos clicar em uma tabela qualquer para poder visualizar a sua estrutura;
(3) Configurações que podem ser realizadas durante a carga;
(4) Nessa opção é possível realizar o mapeamento de várias colunas de forma manual;
(5) Limpa os mapeamentos tanto do Source quanto do Destination;
(6) Limpa o mapeamento apenas do lado do Source;
(7) Colunas do Source e Destination;
(8) Datatype do Source e Destination;
(9) É possível incluir um comando que será executado antes de efetivar a carga, por exemplo, pode incluir um TRUNCATE TABLE, DELETE FROM, chama de uma procedure;
(10) Clicar em Next para avançar.
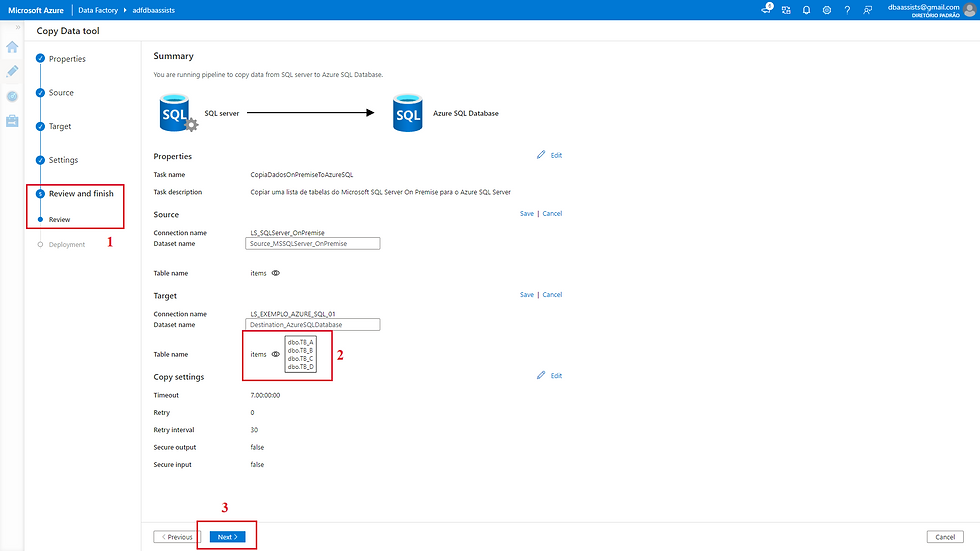
Quando chegamos nessa tela, significa que já estamos próximo do final.
Nesse momento, vamos fazer os ajustes finais, ou seja, incluir algumas estrelhinhas...
(1) Indica que estamos no processo de revisão;
(2) Informações referente ao Pipeline;
(2.1) Ao clicar em Edit o item 2.2 será habilitado;
(2.2) É possível alterar o nome da Pipeline e Incluir uma breve descrição para identifica-lo;
(3) Informações referente ao Source;
(3.1) Ao clicar em Edit o item 3.2 será habilitado;
(3.2) É possível alterar o nome do Dataset do Source;
(4) Apresenta todas as tabelas do Source que serão copiadas;
(5) Informações referente ao Destination (Target);
(5.1) Ao clicar em Edit o item 5.2 será habilitado;
(5.2) É possível alterar o nome do Dataset do Destination (Target);
(6) Apresenta todas as tabelas do Destination (Target) que serão destino das informações;
(7) Informações referente a configuração da Pipeline;
(7.1) Ao clicar em Edit o item 7.2 será habilitado; (7.2) É possível alterar o timeout e outras informações;
(8) Clicar em Next e avançar.

Vamos visualizar como que ficam as alteração.
(1) Indica que estamos no processo de revisão;
(2) Clicar em Edit para habilitar o campo referente ao nome do Dataset do Source;
(2.1) Campo habilitado para renomear o Dataset do Source;
(3) Listagem das tabelas que serão copiadas;
(4) Clicar em Edit para habilitar o campo referente ao nome do Dataset do Destination (Target);
(4.1) Campo habilitado para renomear o Dataset do Destination (Target);
(5) Clicar em Next para avançar.

A próxima tela é apenas um complemento da anterior.
(1) Indica que estamos no processo de revisão;
(2) Listagem das tabelas que receberão as informações;
(3) Clicar em Next para avançar.
Pronto! Configuração concluída, deploy realizado.
(1) Indica que estamos na etapa de deploy;
(2) Indica que o deploy foi realizado com sucesso;
(3) Clicar em Edit Pipeline.

Ao clicar em Edit Pipeline, seremos direcionado para tela abaixo. Nesse momento conseguimos avaliar o processo como um todo.
(1) Nome da Pipeline criada;
(2) Componente que será usado para realizar o loop de carga;
(3) Parâmetro criado para realizar a movimentação dos dados;
(4) Clicar para verificar o fluxo.

Na próxima tela conseguimos visualizar o fluxo de origem da informação.
(1) Nome da Pipeline criada;
(2) Componente Copy data que será responsável pela cópia;
(3) Indica que estamos no fluxo de origem (Source);
(4) Parametrização da tabela;

(1) Nome da Pipeline criada;
(2) Componente Copy data que será responsável pela cópia;
(3) Indica que estamos no fluxo de destino (Target);
(4) Parametrização da tabela;
(5) Possibilidade de incluir um script que deverá ser executado antes da cópia.

Chegamos no final, vamos executar nossa pipeline.
(1) Clicar em Debug;
(2) Apresentação do parâmetro de criação;
(3) Clicar OK para executar.

(1) Nome da Pipeline criada;
(2) Componente que será usado para movimentação dos dados;
(3) Output (log de execução) da execução.


E para finalizar vamos verificar como que as tabelas foram criadas.
(1) Nome do servidor;
(2) Nome do Banco de Dados;
(3) Tabelas criadas.
Conclusão
É isso ai meu amigo, terminamos aqui mais um post. Espero que eu tenha conseguido trazer mais esse conhecimento para você.
Falamos até aqui sobre um recurso muito utilizado tanto por quem trabalha na área de dados ou quem é DBA.
Copiar dados de um ponto ao outro é muito normal!
Quando comecei a trabalhar com Azure Data Factory não sabia que isso também era possível então sempre que precisava recorria para o Import and Export Wizard, mais agora sempre que preciso busco fazer por aqui mesmo.
Espero que tenha gostado. Caso tenha ficado alguma dúvida, pode colocar nos comentários que estarei respondendo.
Um excelente dia para ti e fique com Deus.
Comments