
Data Factory, Trabalhando com Data Flow
- Gabriel Quintella
- 18 de out. de 2021
- 16 min de leitura
Salve salve meu amigo! Que gratidão poder trazer mais um assunto novo até você. Nesse post vou comentar sobre a utilização do Data Flow do nosso Azure Data Factory e fazer uma breve comparação com o Microsoft SQL Server Integration Services.
Mais antes de iniciar, preciso saber se você já ouviu falar, conhece ou já trabalhou com o Microsoft SQL Server Integration Services, mais conhecido como SSIS.
Busquei uma breve descrição para essa incrível ferramenta da Microsoft.
O SQL Server Integration Services é uma plataforma para criar integração de dados em nível empresarial e soluções de transformações de dados. Use Integration Services para solucionar problemas empresariais complexos copiando ou baixando arquivos, carregando data warehouses, limpando e minerando dados e gerenciando objetos SQL Server e dados. Fonte https://docs.microsoft.com/pt-br/sql/integration-services/sql-server-integration-services?view=sql-server-ver15
O SSIS é uma excelente ferramenta de ETL. Não vou aprofundar no assunto SSIS, em breve vou lançar uma série voltada exclusivamente para ele, não percam!
Hoje vamos trabalhar duas formas de importar um arquivo CSV. No primeiro exemplo, vamos ver como que seria via SSIS e no segundo utilizando o Data Flow do Azure Data Factory.
Vamos começar então...
Importando um CSV via Microsoft SQL Server Integration Services (SSIS)
Primeiro passo será você abrir do seu lado o SSIS. Feito isso vamos seguir os passos...
(0) Clicar na setinha pra baixo e em seguida clicar em New Project;
(1) Em Business Intelligence, escolher Integration Service;
(2) Após isso, escolher Integration Services Project;
(3) Informar um nome para o Projeto;
(4) Selecionar um diretório onde o Projeto será criado;
(5) Solution Name é preenchido de forma automática;
(6) Deixar marcado para criar o diretório do Projeto;
(7) Clicar em OK para prosseguir.

Na próxima tela vou fazer uma breve apresentação da tela inicial do nosso projeto.
(1) Área denominada Control Flow, é onde você lida com o fluxo de operações ou Tarefas;
(2) Connection Manager - Área onde as conexões são criadas. É usada para configurar uma conexão entre o SSIS e uma fonte de dados externa;
(3) Solution Explorer - área onde os pacotes, parâmetros e conexões são armazenados;
(4) SSIS Toolbox - área onde estão os componentes que podem ser usados nos pacotes SSIS.
Existe também um outro ponto que não foi mencionado que é o Data Flow, ela a parte do pacote do SSIS, onde os dados são extraídos usando fontes de fluxo de dados. Depois de extrair os dados, podemos aplicar as transformações de fluxo de dados, como conversão de dados, criar uma coluna derivada, é usada também para implementar lógicas de negócios e por último serem gravadas em vários tipos de destinos.

Primeiro passo do nosso projeto será a criação de duas conexões.
A primeira a ser criada será usada para conectar com o nosso arquivo (Source) csv e a segunda será para conectar com o Microsoft SQL Server On Premise (Destination).
(1) Clicar com o botão direito do mouse;
(2) Como estaremos criando uma conexão com um arquivo CSV, vamos escolher New Flat File Connection.
Bora pra próxima tela...

Nesse momento vamos configurar a conexão com o arquivo CSV.
O conector Flat File Connection possui 4 abas: General, Columns, Advanced e Preview.
(0) Aba General;
(1) Informar o nome para a nossa conexão;
(2) Selecionar o local onde está o arquivo;
(3) Selecionar o enconding dos dados;
(4) Selecionar o delimitador de dados caso exista;
(5) Informar se a primeira linha do arquivo possui o cabeçalho ou não;
(6) Clicar em OK para finalizar (não vamos clicar nesse momento, vamos explorar as outras abas).

Continuando a configuração...
(0) Aba Columns;
(1) Não precisa informar novamente o nome para a conexão, esse passo foi realizado anteriormente;
(2) Selecionar o delimitador de linha;
(3) Selecionar o delimitador de coluna;
(4) Prévia dos dados
(5) Clicar em OK para finalizar (não vamos clicar nesse momento, vamos explorar as outras abas).

E para finalizar...
(0) Aba Advanced;
(1) Não precisa informar novamente o nome para a conexão, esse passo foi realizado anteriormente;
(2) Listagem das colunas do arquivo (caso você tenha informado na aba General que a primeira linha é o cabeçalho, ela será carregada e apresentada nesse passo);
(3) É possível alterar o nome das colunas, o tipo do dado (datatype) e etc;
(4) É possível incluir uma nova coluna;
(5) É possível eliminar uma coluna;
(6) Nesse passo é possível sugerir ao SSIS a definição do datatype;
(7) Clicar em OK para confirmar.
Não estarei apresentando a aba Preview, pois ela é bem semelhante a visualização da aba Columns.

Configuração da conexão da conexão com o arquivo CSV concluída, vamos avançar para a configuração da conexão com o Microsoft SQL Service On Premise.
(1) Clicar com o botão direito;
(2) Clicar em New OLE DB Connection.
Vamos avançar para a próxima tela...

Ao clicar em New OLE DB Connection, a tela a seguir será apresentada.
Acompanha aqui comigo...
(1) Clicar em New;
Após clicar em New uma nova tela (Connection Manager) será carregada
(2) Como estaremos usando o Microsoft SQL Server On Premise, vamos selecionar Native OLE DB\SQL Server Native Client 10.0;
(3) Informar o Nome\Instância (Server Name) do SQL Server;
(4) Vamos selecionar User SQL Server Authentication e informar um usuário e senha;
(5) Selecionar o banco de dados;
(6) Clicar em Test Connection para validar a conexão (Dica: Caso os bancos de dados tenham sido listados no passo (5), a conexão já foi validada, ou seja, nem precisa clicar nesse passo);
(7) Clicar em OK para confirmar a configuração.

Bem! Fechamos aqui a configuração das conexões. Precisamos levar em consideração que elas foram criadas da forma mais básica, para melhorar esse processo podemos parametriza-los, mais não é o nosso objetivo por enquanto, quando iniciarmos a série Desbravando o SSIS esses pontos serão esmiuçados.
Vamos avançar agora para a criação do nosso Data Flow e Control Flow.
Agora vai ficar bastante interessante, vamos avançar juntos? Bora então...
(1) Conexões definidas com sucesso;
(2) Vamos adicionar um componente Data Flow Task;
(3) Após incluir vamos renomear ele, para isso basta clicar com o botão F2;
(4) Vamos clicar em Data Flow para desenhar nosso fluxo.

Na próxima tela apresento como que nosso fluxo será composto.
(1) Flat File Source (Source) - será um conector para o arquivo CSV;
(2) Condicional Split - será usado para filtrar apenas os registros do município CAPIXABA;
(3) OLS DB Detination (Destination) - será o conector com o Microsoft SQL Server;

Primeiro passo desse novo ciclo será realizar a configuração do Source.
(1) Arrastar o componente Source Assistant para a área de Data Flow;
(2) Vamos realizar as configurações, basta selecionar caso já existam prontas;
(3) Em Source type, vamos selecionar Flat File;
(4) Selecionar a nossa conexão criada anteriormente;
(5) Será apresentada a informação de onde o arquivo é disponibilizado;
(6) Clicar em OK para concluir.
Bora avançar...

Esse passo é bem semelhante com o anterior...segue ai
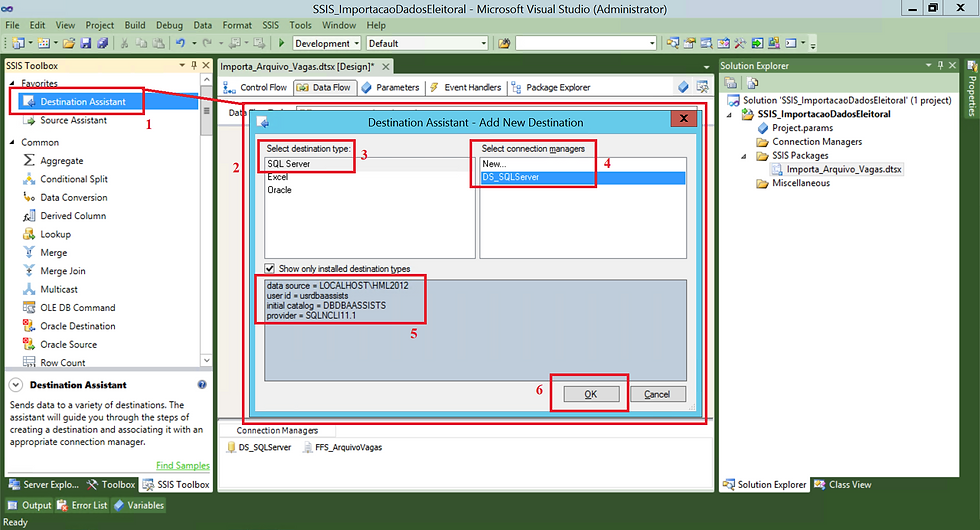
(1) Arrastar o componente Destination Assistant para a área de Data Flow;
(2) Vamos realizar as configurações, basta selecionar caso já existam prontas;
(3) Em Source type, vamos selecionar SQL Server;
(4) Selecionar a nossa conexão criada anteriormente;
(5) Será apresentada a informação de conexão com o nosso banco de dados;
(6) Clicar em OK para concluir.
O próximo passo será configurar o componente Condicional Split.
(1) Adicionar ele na área de Control Flow;
(2) Após clicar duas vezes sobre o componente uma tela será apresentada;
(3) Em Output Name vamos informar um nome para o nosso fluxo e em Condition definir a regra;
(4) Clicar em OK para seguir.

Para relacionar os componentes, basta clicar sobre eles e uma seta azul e uma vermelha serão apresentadas. Vamos seguir os passos agora...
(1) Clicar sobre o componente Conditional Split, após isso clicar sobre a seta azul e arrastar até o componente OLE DB Destination;
(2) Ao realizar essa ligação, esse tela será apresentada para que você posso selecionar o fluxo;
(3) Vamos clicar no botão da setinha pra baixo e selecionar o fluxo que criamos no passo anterior;
(4) Ao escolher, o botão OK será habilitado, basta clicar nele para seguir.

Com o nosso fluxo ponta a ponta criado quase que 100%, vamos criar nossa tabela no Microsoft SQL Server para receber os dados.
(1) Conectar em nosso servidor;
(2) Selecionar nosso banco de dados;
(3) Executar o script para criação da tabela.

Após a criação da tabela, vamos associa-la em nosso componente de destino.
Para isso primeiro passo é clicar duas vezes sobre ele e seguir os passos abaixo.
(1) Nosso componente é composto de três abas: Connection Manager, Mappings e Error Output. Nesse exemplo vamos trabalhar apenas com as duas primeiras. A última é usada para que possamos fazer alguma tratativa em caso de erro na inserção dos dados;
(2) Selecionar a conexão que criamos nos primeiros passos;
(3) Clicar na setinha para selecionar a nossa tabela criada no passo anterior;
(4) Clicar em OK para seguir.

Nesse momento vamos falar da aba Mappings, conforme o próprio nome, ela serve para realizar o mapeamento entre as colunas da origem com o destino.
(1) Aba Mappings;
(2) Colunas do Source;
(3) Colunas do Destination;
(4) O SSIS permite que você faça o mapeamento automático a partir da igualdade de nome entre as colunas. Para realizar isso, basta clicar na área em branco existente entre as colunas do Source e Destination e selecionar a opção Map Items by Matching Names;
(5) Mapeamento realizado, basta clicar em OK para seguir.

Apenas para reforçar uma informação já passada acima, é possível e recomendado que você nomeie todos os passos do seu fluxo, isso facilita tanto no entendimento do seu processo quanto na resolução de algum eventual erro.
Para realizar isso é bem simples. Segue comigo...
(1) Clicar sobre o componente, clicar com o botão direito do mouse e selecionar a opção Rename, caso seu SSIS esteja em inglês.
Você também consegue realizar essa mesma operação clicando sobre o componente, apertando o botão F2 e digitando o nome do seu fluxo.
Bem simples, viu!

Pronto! Agora podemos dizer que nosso fluxo está completo! De ponta a ponta.
(1) Fluxo de cópia de dados de um arquivo CSV para o Microsoft SQL Server.

Depois de tudo pronto, vamos para execução! Será que vai funcionar? Vamos ver...
Mais antes de partir para execução, vou falar de um recurso bem interessante que existe no SSIS que é o Data Viewer. Ele permite que você visualize os dados durante a sua execução.
Você pode configura-lo de duas formas.
Primeiro:
(1) Clicar com o botão do mouse sobre a seta;
(2) Clicar em Enable Data Viewer.
Esse modelo não dá opção de selecionar as colunas. Para pode selecionar, após os dois passo acima, você precisa seguir os passos abaixo para escolher as colunas que deseja visualizar.

E de outra forma:
(0) Indicativo de que estamos na tela do Data Viewer;
(1) Clicar duas vezes sobre a seta azul;
(2) Clicar para habilitar os passos (3) e (4);
(3) Opção de movimentar as colunas de um lado para o outro, você também pode fazer isso clicando duas vezes sobre as colunas ou arrastando;
(4) Todas as colunas que estiverem nessa posição serão apresentadas durante a visualização.
(5) Clicar em OK para seguir.

Após essa breve explicação, vamos a execução propriamente dita.
(1) Fluxo em execução;
(2) Linhas filtradas;
(3) Apresentação das informações no Data Viewer.

Com isso finalizamos nosso processo de carga de dados via SSIS.
(1) Origem do arquivo CSV;
(2) Filtro de município;
(3) Carga de dados no Microsoft SQL Server.

Vamos visualizar agora pelo Client do Microsoft SQL Server.
(1) Consulta na tabela dbo.consulta_vagas;
(2) Dados carregados.

Acabou que na empolgação esqueci de um ponto importante.
Vocês repararam que não existe em nosso fluxo um ponto de validação de existência de registros em nossa tabela. Mediante isso, inclui um passo anterior ao de carga que é para limpar a tabela (TRUNCATE TABLE) sempre antes de carregar.
Dessa forma garantimos que não vamos ter dados repetidos em nossa tabela.
Acompanha aqui rapidinho...
(1) Inclusão de um componente de script SQL, Execute SQL Task. Após incluir basta clicar duas vezes;
(2) Após clicar duas vezes uma janela será aberta. Vamos clicar nessa linha para incluir o script;
(3) Escrita do comando SQL;
(4) Clicar em OK para confirmar o comando;
(5) Informar um nome para nosso componente.

E ai meu me amigo, me conta, gostou? Preparado para embarcar na nova aventura?
Importando um CSV via Data Factory - Data Flow
Nesse exato momento, vou demonstrar como que você constrói esse mesmo fluxo porém agora dentro do Azure Data Factory usando o Data Flow. A lógica é a mesma, vamos possuir uma origem, um componente para filtrar somente os dados que desejamos trabalhar e por fim um destino.
Como sempre, deixarei um plus. Quando trabalhamos o passo anterior com o SSIS , não aplicamos nenhum tratamento de dado, porém como Data Flow do Azure apresentarei para você como que fica. É bem simples, útil no nosso dia a dia e tenho certeza de que você irá curtir. Então segue aqui comigo.
Antes iniciarmos, primeiro você precisa realizar o login no seu Azure Data Factory, basta clicar aqui.
Após realizar o login, basta clicar em nosso ícone do lápis que estaremos em nossa área Author.
Feito isso, bora trabalhar, porque o tempo ruge e a Sapucaí é grande!
(1) Vamos clicar no botão +;
(2) E depois clicar em Data Flow.

Após clicar em Data Flow, você será redirecionado para a tela abaixo.
(1) Uma breve introdução será apresentada pelo Azure Data Factory, basta clicar em Finish;
(2) Observe que um objeto na pasta Data Flow já foi criado;
(3) Informar um nome para nosso Data Flow.

Feito isso, vamos clicar em Source e configurar nossa primeira origem de dados.
(0) Aba Source settings;
(1) Nome do nosso Data Flow;
(2) Vamos clicar sobre o nosso componente para começar a configuração;
(3) Vamos informar um nome para esse componente, da mesma forma que fizemos com o SSIS;
(4) Selecionar o tipo do Source (Maiores detalhes https://docs.microsoft.com/en-us/azure/data-factory/data-flow-source);
(5) Selecionar o Dataset para conexão com o nosso dado;
(6) Selecionar qual opção deseja (Maiores detalhes: https://docs.microsoft.com/en-us/azure/data-factory/concepts-data-flow-schema-drift);
(7) Podemos definir uma amostra de dados ou todos os dados do nosso source. Isso é útil quando você precisa apenas de uma amostra de seus dados de origem para fins de teste e depuração.
Segue comigo...

Nessa próxima tela trago uma informação importante quando falamos sobre nomenclatura dos componentes.
Observem o erro no (1), para nome de componentes dentro de um Data Flow, são permitidos apenas caracteres alfabéticos (letras e números), ou seja, forcei a separação dos nomes com um underline e apresentou erro.
Foi apenas uma observação, nada demais! Pois eu tenho um costume de separar os nomes com underline, caso você também tenha, fique atento porque isso não é permitido no Data Flow, quando trabalhamos com outros componentes do Azure Data Factory, isso é possível!
Bora avançando...

Após realizar a nomenclatura correta, o processo pode seguir fluindo...

Continuando em nosso componente de Source, vamos falar um pouco sobre a aba Projection.
(0) Aba Projection;
(1) Colunas/Datatype da origem;
(2) Datatype da origem;
(3) Vamos alterar o Datatype da coluna DT_GERACAO (Esse é o plus que comentei acima, não perca os detalhes).
Essa aba é bem interessante, pois ela apresenta toda a estrutura (colunas e datatypes) da nossa origem além permitir você alterar.
Essa opção não existe até o momento quando estamos trabalhando com o componente Copy Data dentro de uma Pipeline, pois a sua utilização deve ser restrita a cópia de um dado bruto do ponto A para o ponto B.
Tratamento de dados devem ser feito no Data Flow, lembrando que quando trabalhamos com o processo de Big Data, aplicamos conceitos de ELT e não de ETL.
Vamos explicando mais a frente com maiores detalhes.

Conforme mencionado acima, nessa tela é possível fazer a alteração de um datatype.
(0) Aba Projection;
(1) Coluna DT_GERACAO;
(2) Novo formato do dado.

Após a configuração, observe como que fica.
(0) Aba Projection;
(1) Coluna/DataType/Format.

As demais abas não serão abordadas, caso tenham interesse em conhecê-las com detalhes, basta acessar a documentação oficial no link.
Source configurado, agora vamos incluir nosso componente para filtrar apenas as informações que precisamos para trabalhar.
Dando três passos lá traz, você lembra que quando trabalhamos com o SSIS , fizemos uso do componente Conditional Split, pois bem, ele também existe no Azure Data Factory, mais em nosso exemplo, usarei o componente Filter.
Sua utilização é bem semelhante ao Conditional Split, acompanha aqui comigo...
(1) Vamos clicar no componente de Source;
(2) Ao realizar o clique, um símbolo de será apresentado, vamos clicar sobre para listar as opções;
(3) Selecionar o componente Filter.

Após clicar sobre o o componente de Filter, o mesmo será carregado na tela do Data Flow, vamos falar um pouco da sua configuração.
Vamos clicar sobre o componente Filter e iniciar a configuração.
(0) Aba Filter Settings;
(1) Componente de Filter;
(2) Informar um nome para o componente dentro do fluxo;
(3) Informar qual que é o passo predecessor do componente Filter;
(4) Etapa onde é definida a regra para seleção dos registros;
(5) Regra aplicada;
(6) Ao clicar sobre o link Open Expression Builder, o construtor de apoio a criação da regra é apresentado;

Cliquei no link para que você ver como que funciona pelo construtor.
(1) Informativo de que está no construtor de regras;
(2) Área para criação da sua regra;
(3) Algumas opções para auxiliar na construção da regra;
(4) O componente possui expressões para construção de regras ;
(5) Ao clicar nos grupos do item (4), as regras são carregadas nesse item;
(6) É possível validar a regra criada;
(7) Opções de salvar ou cancelar;
(8) Acesso a documentação oficial da Microsoft.

No passo anterior, finalizamos a criação da configuração do nosso componente de Filter, nesse momento vamos iniciar a configuração do Destination. Acompanha aqui comigo...
Primeiro passo é clicar sobre o componente de Filter, clicar sobre o sinal de + e selecionar Sink.
(0) Componente de Sink;
(1) Quando adicionamos o componente de Sink, um passo a passo é apresentado, para concluir basta clicar em Finish;
(2) Informar um nome para o nosso componente;
(3) Selecionar o passo predecessor;
(4) Selecionar o tipo de destino (Maiores detalhes: https://docs.microsoft.com/en-us/azure/data-factory/data-flow-sink);
(5) Dataset que será usado para carregar os dados;
(6) Outras opções (Maiores detalhes: https://docs.microsoft.com/en-us/azure/data-factory/concepts-data-flow-schema-drift).

Vou detalhar agora os passos da configuração.
(0) Aba Sink;
(1) Fluxo da informação;
(2) Configuração pronta para a aba Sink.

Acompanha aqui comigo...
(0) Aba Settings;
(1) Componente de Sink;
(2) Método disponíveis para carregar a informação (vou detalhar mais a frente);
(3) É possível fazer a criação da tabela (Recreate table) no momento da execução, limpar (Truncate table) ou não fazer nada (None);
(4) É possível fazer a utilização do banco TempoDB (vou detalhar mais a frente);
(5) É possível executar algum script antes de carregar;
(6) É possível executar algum script após carregar.

Vamos nesse momento tratar das configurações referente ao mapeamento das colunas entre o Source e o Sink.
(0) Aba Mappings;
(1) Componente de Sink;
(2) Quando essa opção está habilitada, significa que o mapeamento é feito de forma automática, caso encontre nomes idênticos entre Source e Sink, o mapeamento é feito;
(3) Apenas uma informação de que o mapeamento é feito pela igualdade na nomenclatura;
(4) Outras configurações (irei detalhar mais a frente).
Skip duplicate input columns - Se a mesma coluna de entrada for usada em mais de um mapeamento, essa coluna de entrada será ignorada nos mapeamentos após o primeiro;
Skip duplicate output columns - Se um mapeamento resultar na mesma saída de um mapeamento anterior, então essa saída de mapeamento será ignorada.

Nessa próxima tela, apresento como que seria a tela de Mappings com a opção de Auto Mapping desabilitada.
(0) Aba Mappings;
(1) Componente de Sink;
(2) Opção de Auto Mapping desabilitada;
(3) Nessa momento existe 3 opções quanto ao mapeamento:
Reset - elimina todos os mapeamentos existentes;
Add mapping - Adiciona uma linha para realizar o mapeamento;
Delete - Elimina um ou vários mapeamentos realizados, basta selecionar a(s) linhas que deseja eliminar;
(4) Mapeamento propriamente dito;
(5) Colunas do Source;
(6) Colunas do Sink;
(7) Opção para eliminar o mapeamento.

Na próxima tela, vamos visualizar como que o mapeamento ficou, isso é feito na Inspect (0).
(1) Componente de Sink;
(2) Conseguimos ter uma visão do Input/Ourput;
(3) Mapeamento.

E por fim conseguimos também visualizar os dados. Para isso vamos navegar na aba Data preview (0).
(1) Componente de Sink;
(2) Opa! Uma mensagem de erro ou melhor Warning!
(3) Para poder visualizar os dados, primeiro precisamos habilitar o Data Flow debug que é um serviço que só via spark. Demora um pouquinho, quando estiver disponível estará marcado de verde e os dados passarão a aparecer.

Quando clicamos para habilitar o modo debug, uma tela na direita será apresentada onde realizamos algumas configurações do debug.
Link para maiores detalhes: https://docs.microsoft.com/en-us/azure/data-factory/iterative-development-debugging

Na próxima tela conseguimos verificar que o Debug já foi iniciado.
(1) Clicar no componente de Sink;
(2) Clicar na aba Data preview;
(3) Debug sendo iniciado.

Agora com o Debug ativado, conseguimos visualizar uma prévia dos nossos dados.
(1) Clicar no componente de Sink;
(2) Clicar na aba Data preview;
(3) Debug iniciado;
(4) Amostra dos dados que serão carregados.

Podemos visualizar que os dados apresentados na tela anterior não existem em nosso destino.
(1) Servidor que os dados serão carregados;
(2) Banco de dados;
(3) Tabela que receberá os dados;
(4) Consulta na tabela;
(5) Resultados da consulta, NENHUM DADO!
Ou seja, o que vimos anteriormente é uma prévia do que será carregado. Fantástico né! No SSIS isso só é possível quando iniciamos a carga e colocamos um Data Viewer.

Antes de iniciar a carga, vamos validar nosso fluxo, é bem simples!
(1) Vamos clicar em Validate;
(2) Caso tenha alguma inconsistência, ela é apresentada nessa janela.
Sem pendências, vamos clicar em SAVE para salvar nosso fluxo.

Para executar nosso fluxo, precisamos criar uma Pipeline para chamar nosso Data Flow.
Coisa mais fácil! Acompanha aqui comigo...
(1) Na aba Pipeline;
(2) Vamos clicar nos três pontinhos (...) e na janela que será apresentada, clicar em New Pipeline;

Após clicar em New Pipeline, vamos fazer algumas configurações básicas
(0) Informar um nome para a Pipeline;
(1) Na aba Activities;
(2) Move & transform;
(3) Incluir um objeto do tipo Data Flow;
(4) Na aba General;
(5) Informar um nome para o nosso componente;
(6) Objeto será salvo na pasta de objetos Data flows.

Na próxima tela, vamos fechar a configuração da nossa Pipeline.
(1) Clicar sobre o componente Data Flow;
(2) Aba Settings;
(3) Data Flow selecionado;
(4) Configurações referente ao Debug;
(5) Clicar em Debug para executar.

Que lindo meu amigo, execução realizada com sucesso!
(1) Componente Data Flow;
(2) Aba Output;
(3) Log de execução.

Vamos analisar agora o nosso Output.
(1) Cabeçalho do log;
(2) Fluxo passando pela origem, filtrando os dados e gravando no destino;
(3) Resumo do que foi feito;
(4) Status da execução;
(5) Tempo total de execução da Pipeline;
(6) Tempo de processamento da informação;
(7) Total de linhas escritas;
(8) Estágios do fluxo;
(9) Passos.

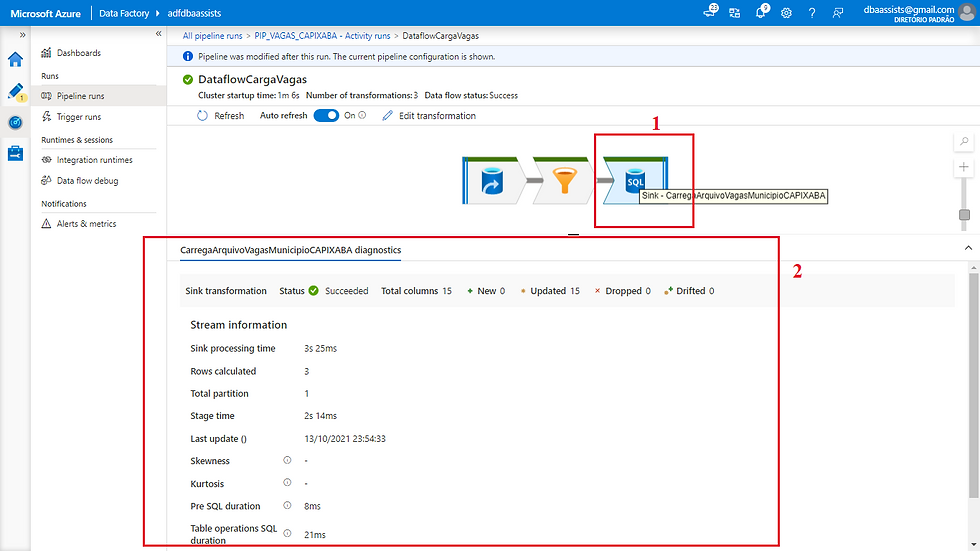
Vamos agora abordar cada passo do nosso fluxo.
(1) Componente de conexão com a origem;
(2) Informações do status de leitura do objeto, quantidade de linhas lidas, tempo gasto, data de execução, entre outras informações.

(1) Componente de filtro de dados;
(2) Informações do status de leitura do objeto, quantidade de linhas filtradas, se o processo foi particionado para ganho de performance, tempo gasto, data de execução, entre outras informações.

(1) Componente de conexão com o destino;
(2) Informações do status do objeto, quantidade de linhas gravadas, tempo gasto, data de execução, entre outras informações.
Vamos agora consultar nossos dados gravados? Simbora lá...
(1) Conectar com o servidor;
(2) Banco de dados;
(3) Tabela em que os dados serão gravados;
(4) Consulta;
(5) Dados carregados.
(6) Ops! Huston we have a problem!
Isso mesmo, uma coluna apresentou um comportamento indesejado! Vamos tratar...

Conforme observamos acima, a coluna DT_GERACAO foi armazenada sem dados, ou seja, tudo NULL.
Isso ocorreu devido a um erro em nosso tratamento aplicado quando tentamos converte-la de STRING para DATETIME.
O que precisamos fazer para esse caso é adicionar um componente para fazer a conversão desse dado para um dado do tipo DATETIME.
Vamos ver como que fica...
Primeiro passo é voltar em nosso Data Flow.
(1) Após abrir o Data Flow, vamos clicar em nosso componente de source e em seguida clicar no sinal de + para expandir as opções;
(2) Na combo que será apresentada, vamos selecionar a opção Derived Column.

Após isso, o componente será adicionado em nosso fluxo.
(1) Clicar sobre o componente adicionado;
(2) Aba Derived columns setting;
(3) Informar um nome para nosso componente;
(4) Selecionar quem será o fluxo predecessor;
(5) Podemos adicionar uma tratativa, duplicar uma existente, eliminar uma existente ou abrir o construtor de expressões;
(6) Local onde incluímos a nossa regra.

Antes de construir a regra, vamos dar um passo atrás e alterar o tipo de dado no nosso componente de Source.
Esse passe é importante pois no inicio definimos que ele seria do tipo date e precisamos voltar ele para string.
Para fazer isso é bem simples, segue aqui comigo.
(1) Clicar sobre o componente de Source;
(2) Selecionar a coluna desejada e na coluna Type selecionar String;
(3) Clicar em SAVE.

Após alterar, vamos voltar no nosso componente de Derived Column, clicar sobre o componente e clicar em Open expression builder.
Feito isso, basta seguir os passos abaixo.
(1) Indicador que estamos na tela de construção de regras;
(2) Informar um nome para a coluna q será criada;
(3) Reflete a informação do passo (2);
(4) Local onde é feita a escrita da regra;
(4.1) Clicar para salvar a edição;
(5) Prévia de como ficarão os dados;
(6) Coluna nova que refletirá a regra criada;
(7) Coluna original sem tratamento;
(8) Opção de salvar ou cancelar;
(9) Acesso a documentação da Microsoft.

Feito isso, vamos voltar em nosso Data Flow e visualizar como que ficou.

Passo seguinte é refazer o mapeamento das colunas, dessa vez usando a coluna com a regra criada.
(1) Clicar no componente de Sink e selecionar a aba Mapping;
(2) Componente que criamos a nova coluna;
(3) Selecionar a colunar a criada no passo (2).

Vamos voltar e realizar uma outra configuração para não permitir duplicidade de registros em nosso destino.
O componente Sink permite duas opções:
Escolher o TRUNCATE TABLE em table action ou;
Em Pré SQL script a definição de algum comando que será executado antes da carga;
Vamos seguir e ver como que irei fazer...
(1) Clicar no componente de Sink;
(2) Aba Settings;
(3) Em Table action, selecionar TRUNCATE TABLE;
(4) E deixar em branco Pré SQL script;
(5) Clicar em SAVE para gravar a alteração.

Alterações realizadas, vamos executar nossa Pipeline e visualizar os dados.
Após execução, vamos consultar os dados.
(1) Conectar com o servidor;
(2) Banco de dados;
(3) Tabela em que os dados serão gravados;
(4) Consulta;
(5) Dados carregados.
(6) Bingo! Perfect!

Muito bem, dados carregados com sucesso! Parabéns.
Com isso meu amigo, finalizamos mais um post rico em detalhes.
Conclusão
Meu amigo é como muita gratidão que conseguimos alcançar mais um objeto.
Espero que tenha conseguido demonstrar nesse post como que podemos usar o Data Flow do Azure Data Factory, um componente de extrema importância para você que trabalha com BI ou Big Data.
É um componente que combinado com o Copy Data faz um dupla perfeita, pois o primeiro fica com o papel de copiar os dados da origem e o segundo com o trabalho bruto de trabalhar o dado para deixa-lo disponível para consumo, fechando assim todo o ciclo de ELT.
Mais uma vez agradeço a sua atenção, sua dedicação e queria muito ouvir a sua opinião e sugestão sobre tudo isso que falamos aqui.
Grande abraço e fique com Deus!
Até o próximo...
Comentários