
Fala meu querido, tudo bem? Espero que sim. No post anterior apresentei para você um importantíssimo recurso do Azure Data Factory chamado Linked Service. Recurso esse que tem como finalidade promover uma ligação com o nosso dado seja ele para ser usado para definir um dado de origem ou destino.
Neste post, trabalharemos com outro componente chamado Dataset. Enquanto o Linked Service promove a ligação é no Dataset que vamos definir como iremos trabalhar manipulando essa informação. Em resumo, o Linked Service complementa o Dataset, podemos também dizer que Dataset não existe sem Linked Service.
Por exemplo, podemos acessar um arquivo armazenado em um Blob e carrega-lo em um banco de dados, ou transporta-lo para outro Blob, pra um FTP, ou seja, uma enormidade de formas.

Gostaria muito que você prestasse bastante atenção nos próximos detalhes, eles serão muito úteis para você!
O Dataset é um componente que deve ser tratado com muita atenção, moderação e carinho. Pois caso ele seja construído de uma forma errada, sua administração vai se transformar em um verdadeiro transtorno, sendo bem radical, um verdadeiro inferno de Dante.
Falo isso por experiência, senti isso na pele! Não recomendo pra ninguém. Foi um caos, mais entre mortos e feridos, salvaram-se todos. Vou contar um pouco para que você possa entender as proporções que um mal uso de um recurso tomou!
Não conhecia o Azure Data Factory, não conhecia os conceitos, seus componentes, como que funcionavam, muito menos conhecia o recurso de parametrização, primeiro erro cometido! Começar a trabalhar com algo se antes estudar um pouco! Então para tudo (arquivo, banco de dados, API, FTP) que eu precisa manipular, um Dataset novo era criado! Cada passo alcançado era uma vitória, comemorava, estava achando que já conhecia a ferramenta, mano do céu, chegou um momento que existia mais de 300 Datasets, uma loucuraaaaaaaaaaaaa. Como não conhecia os impactos, segui meu caminho.
O tempo foi passando e o que era meu estava guardado, em um belo dia, o vulcão de Dante entrou em erupção! Começaram os impactos no Devops, quando precisava transportar algo para produção e a esteira do DevOps era iniciada, nada subia pra produção pois o arquivo Arm Template chegou no seu limite, ou seja, aquilo que era bom, pelo menos eu achava, ficou péssimo! Tive que parar tudo que estava fazendo para corrigir, não satisfeito com os argumentos, procurei entender mais sobre o assunto, e logo percebi que estava seguindo para um caminho extremamente péssimo, nebuloso. Mais enfim, foi quase uma semana de trabalho jogado no lixo, mais ficou lindo, rodando suave e serviu como uma lição aprendida.
Dataset genérico é vida! Parametrize sempre, faça sempre pensando em reutilização, sua vida será tranquila e terá paz!
Bem diante desse relato emocionante, vou apresentar duas formas de você configurar seus Dataset. Primeiro irei apresentar a que me deu maior trabalho e depois a solução de todos os meus problemas. Por fim deixarei um bônus para você!
Segue então aqui comigo....
Primeiro Caso - Dataset Simples
Na tela abaixo abaixo vamos iniciar a criação de um Dataset simples e problemático.
Por que simples? Não entendi...
Simples a resposta...Esse Dataset estará usando um Linked Service apenas para carregar arquivos de um diretório especifico, em nosso caso em um Blob.
Vamos começar pela criação de uma Pipeline!
(1) Escolher um nome para a Pipeline;
(2) Em Activities, escolher o componente Copy Data;
(3) E ele será carregado no Control Flow.

Vamos fazer agora a configuração do Source (0) do nosso dado.
(1) Clicar em New;
(2) Como vamos conectar com um Blob, devemos selecionar Azure;
(3) Escolher Azure Blob Storage.

(1) Como nosso arquivo é um CSV, então vamos escolher DelimitedText.

(1) Vamos escolher um nome para o nosso Dataset;
(2) Selecionar o Linked Service criado no post anterior. Caso não tenha lido, basta clicar aqui.

(1) Vamos clicar em Open this dataset.
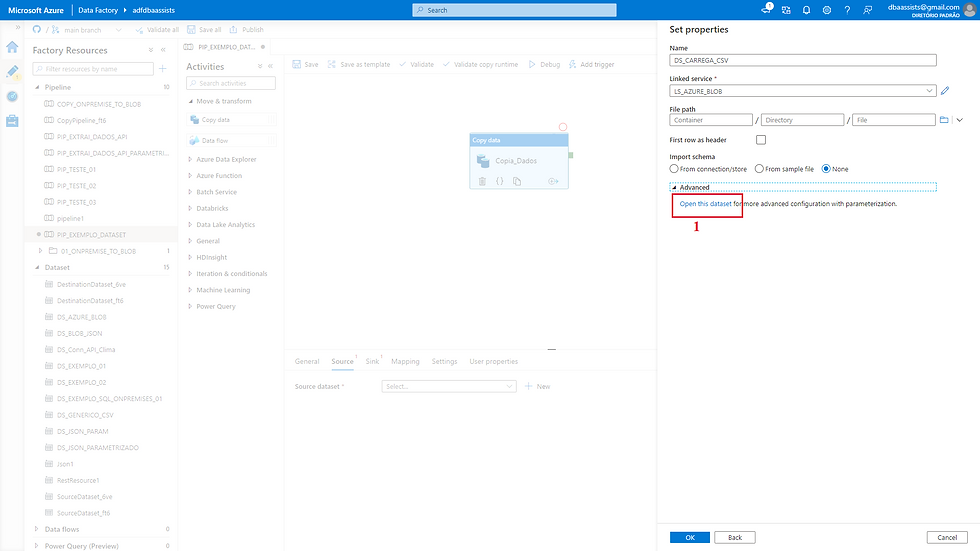
Pronto! Agora precisamos apenas ajustar alguns ponteiros.
Vamos complementar a configuração do Dataset.
(1) Selecionar o diretório (dentro da storage account) que está o arquivo;
(2) Selecionar o delimitador de colunas;
(3) Selecionar o encoding dos dados;
(4) Informar se a primeira linha do arquivo contém o cabeçalho.
Existem outras configurações que podemos trabalhar, mais vamos ficar apenas nessas por enquanto.

Vamos iniciar então,
(1) Após clicar em Browser, uma tela a direita será apresentada para que seja possível escolher um arquivo;
(2) Selecionar o arquivo;
(3) Clicar em OK.

Pronto!
Item (1) configurado com sucesso!
Para o item (2) vamos deixar selecionado Semicolon (;).
No item (3) deixar o Default(UTF-8)
E em relação do cabeçalho (4) vamos deixar marcado.

Nesse modelo de Dataset conseguimos também realizar o mapeamento das colunas a partir do Source. Veja como que fica!
(1) Vamos clicar em Schema;
(2) Feito isso, vamos clicar em Import Schema;
(3) Após você clica no botão Import Schema, duas opções são carregadas:
From sample file - nessa opção você pode escolher o arquivo que deseja ser mapeado e;
From connection/store - quando você escolher essa opção, o arquivo que você especificou anteriormente (no item (1)) é usado como origem.

Pronto! Lindo demais! Mapeamento de campos realizado com sucessoooooooo!!!

Source configurado com sucesso, vamos agora configurar o nosso Sink (Destino ou Target seja lá o nome que queira usar hahaha).
(1) Vamos clicar em Sink;
(2) Clicar em New;
(3) Selecionar um nome para o nosso Dataset;
(4) Vamos selecionar o nosso Linked Service para armazenar os dados, nesse exemplo será em nosso Azure SQL;
(5) Selecionar em qual tabela estaremos armazenando os dados;
(6) Clicar em OK.

Feito isso, conseguimos visualizar como que ficou o Dataset do nosso destino.
(1) Clicar em Connection;
(2) Visualizar o Linked Service e a tabela de destino.

Para mapeamento das colunas da tabela, vamos fazer do mesmo modo que fizemos com o Source.
Porém como uma diferença, no Source possuíamos duas opções de mapeamento, agora nesse caso que é para uma tabela, ele assume que ele deve mapear os campos exatamente da tabela selecionada.
(1) Selecionar Schema;
(2) Clicar em Import Schema;
(3) Listagem das colunas com seu tipo de dado.

Origem e destino configurados, agora vamos relacionar cada campo.
Como nesse exemplo os campos são iguais, ao clicar em Import Schema, a associação é realizada de forma automática. Vejo como que é feito.
(1) Clicar em Mapping;
(2) Clicar em Import Schema;
(3) Colunas relacionadas.

Para concluir, vou adicionar um script que é executado antes da carga de dados.
Nesse caso, SEMPRE, antes de carregar vou TRUNCAR a tabela.
É uma atividade bem simples, acompanha comigo.
(1) Clicar em Sink;
(2) Em Pré-copy script, vamos colocar "TRUNCATE TABLE NOME_TABELA".

Configuração realizada, basta clicar em SAVE e testar seu processo de carga de dados!
SEGUNDO CASO - Dataset Parametrizado
Agora vamos ver como que fica a mesma configuração porém dessa vez parametrizando os Dataset de Origem e Destino.
Além disso vamos trabalhar também com outro Linked Service que criamos parametrizando qual a Azure Storage Account vamos acessar, caso não tenha acompanhado no post anterior, clique aqui.
É bem simples....Segue os passos comigo!
(1) Selecionar para criar uma Pipeline e após escolher um nome para a Pipeline;
(2) Em Activities, escolher o componente Copy Data;
(3) E ele será carregado no Control Flow.
(1) Clicar sobre o componente Copy Data
(2) Clicar em New;
(3) Escolher Azure Blob Storage.

(1) Como nosso arquivo é um CSV, então vamos escolher DelimitedText e após isso clicar em Continue (2).

Na tela abaixo vamos realizar a configuração do nosso Dataset de Origem. Bora lá...
(1) Informar o nome para o Dataset;
(2) Selecionar o nosso Linked Service;.
(3) E por último, clicar em Open this dataset.

Após clicar em Open this dataset, vamos realizar agora a parametrização do nosso Dataset.
(1) O Linked Service que selecionamos também é do padrão parametrizado, então nesse ponto vamos informar o nome da nossa secret;
(2) Vamos informar os parâmetros para acesso ao nosso Blob;
(3) Vamos informar o delimitador de coluna;
(4) Selecionar o encoding;
(5) E por ultimo informar se a primeira linha possui o cabeçalho das colunas.

Pronto, vamos fazer a parametrização do item (2).
(1) Vamos clicar em Parameters;
(2) E criar três parâmetros:
container
diretorio
arquivo

Após a criação, vamos associa-los aos campos. Muito fácil....
Para ambos os três (container, diretorio e file) o passo é o mesmo:
(1) Clicando no campo, será apresentada a opção Add dynamic content;
(2) Após clicar, vamos selecionar o parâmetro correspondente a cada campo;.
(3) O parâmetro será carregado no quadro acima.
Após isso basta clicar em OK.

Configurações realizadas, vamos verificar como que ficou!
(1) Parâmetro para a secret de conexão com o Linked Service;
(2) Parâmetros para acesso ao Blob;
(3) Delimitador de coluna;.
(4) Definição do Encoding;
(5) Marcação de que a primeira linha possui o cabeçalho das colunas;
(6) Clicar em SAVE para concluir a configuração.

Agora vamos configurar o Sink (Destino).
(1) Clicar em Sink;
(2) Clicar em New;
(3) Vamos selecionar um Linked Service do Azure SQL, digite SQL;
(4) Clicar em Azure SQL Database;
(5) Clicar em Continue.
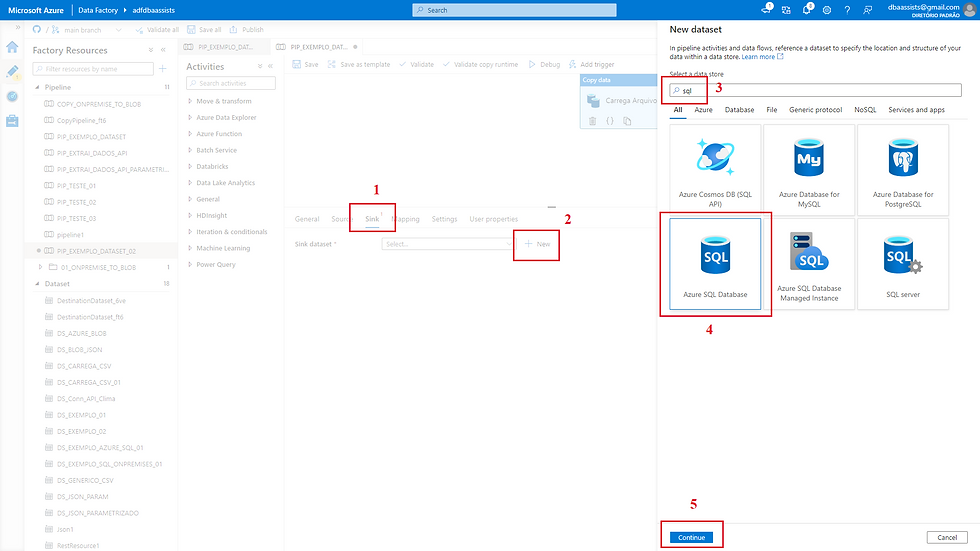
Nessa tela agora vamos dar continuidade na configuração do nosso Dataset de destino.
(1) Informar um nome para o Dataset;
(2) Selecionar o Linked Service;
(3) Vamos clicar em Open this dataset;
(4) Clicar em OK.

No próximo passo vamos criar os parâmetros para informar o schema e o nome da tabela.
(1) Clicar em Parameters;
(2) Criar dois parâmetros:
schema
tabela

Vamos agora associar os parâmetros criados aos campos.
(1) Clicando no campo a opção Add dynamic content será habilitada, vamos clicar nela;
(2) Selecionar o parâmetro desejado;
(3) A informação será carregada na tela acima.
(4) Clicar em OK.

Para a tela abaixo, os passos são os mesmos da anterior.

Quase lá jovem mancebo!!!!
Vamos agora realizar a parametrização para o nosso processo de limpeza dos dados antes da cópia.
(1) Clicar no campo Pre-copy script, a opção Add dynamic content será habilita. Quando isso ocorrer vamos clicar nela para informar os valores;
(2) No quadro vamos digitar o script para criar de forma dinâmica o script de TRUNCATE TABLE;
(3) Clicar em OK para finalizar.

Ufa! Configuração concluída! Olha como que ficam as variáveis.
Basta clicar em SAVE para finalizar a configuração.

Agora para testar, basta informar os parâmetros.

Terceiro Caso - Criar uma Pipeline com Dataset Parametrizado Carregando Vários Arquivos
Agora vou deixar um plus para você!
No exemplo abaixo vou apresentar para você como que é possível ler um diretório e carregar todos os arquivos contidos nele.
Nesse exemplo vamos fazer a leitura do nosso Blob. Para isso vou utilizar o componente Get Metadata, antes de carregar vamos colocar um procedimento para apagar os registros. Para isso vamos utilizar uma procedure, que será chamada a partir do componente Storage Procedore e por último para carregar todos os arquivos utilizaremos o componente For Each e dentro dele o Copy Data.
Muito coisa né? Mais é bem simples! Acompanha aqui comigo...
Vamos criar uma Pipeline nova e em Activities, dentro de General, vamos selecionar o componente Get Metadata (1).
Feito isso o componente será carregado no Control Flow, basta seguir os passos para concluir.
(2) Clicar sobre o componente;
(3) Clicar em New;
(4) Informar um nome para esse componente;
(5) Selecionar o Linked Service criado;
(6) Vamos clicar em Open this dataset.
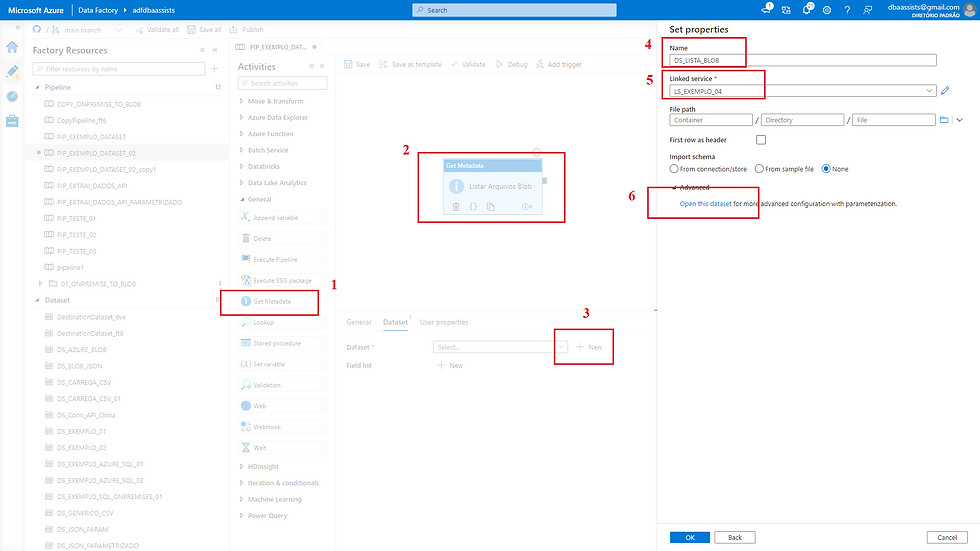
Vamos parametrizar o nosso Dataset com os seguintes parâmetros:
(1) Criar um parâmetro para receber a secret de conexão com o Blob;
(2) Criar um parâmetro para receber o nome do container;
(3) E por último um parâmetro para receber o nome do diretório.
Após a criação basta clicar em SAVE.

Após salvar as alterações veja como que fica a nossa parametrização.
(1) Nome do nosso Dataset;
(2) Parâmetros criados no passo anterior;
(3) Selecionar child items.
Vamos clicar em SAVE para confirmar e no próximo passo vamos executar esse passo criado para visualizar os arquivos listados do diretório.

Quando executamos, o componente faz uma leitura em nosso diretório e retorna todos os arquivos encontrados.

Beleza! Primeira etapa concluída. Vamos agora incluir um componente para realizar a exclusão dos dados antes de carregar.
Para isso vou selecionar o componente Storage Procedure. Conforme o próprio nome, esse componente faz a chamada de uma procedure.
Em nosso banco de dados vou criar uma procedure que irá receber dois parâmetros e executará o comando TRUNCATE TABLE.
Antes de prosseguir no Azure Data Factory, vou deixar o script de criação da nossa procedure.
/****** Object: StoredProcedure [dbo].[sp_trucate_tabela] ******/
IF EXISTS (SELECT 1 FROM sys.procedures WHERE NAME = 'sp_trucate_tabela')
DROP PROCEDURE [dbo].[sp_trucate_tabela]
GO
/****** Object: StoredProcedure [dbo].[sp_trucate_tabela] ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create PROCEDURE [dbo].[sp_trucate_tabela] @schema varchar(10) , @tabela varchar(100)
as
begin
declare @sql varchar(1000)
set @sql = 'truncate table ' + @schema + '.' + @tabela
exec(@sql)
end
GO
Pronto, basta copiar o script e criar em seu banco de dados. Bora prosseguir...

Vamos fazer a criação de 2 parâmetros.
Em Stored procedure parameters, vamos clicar em New duas vezes, pois a nossa procedure espera receber dois parâmetros. Onde um será responsável por receber a informação de schema e o outro o nome da tabela.
Feito isso basta clicar em SAVE.

Agora estamos chegando no final.
Vamos incluir o nosso componente de For Each para realizar a carga de um arquivo por vez.
Acompanhe como é bem simples...

Vamos clicar sobre a aba Settings, vamos clicar sobre Items, a opção Add dynamic content será habilitada. Feito isso, vamos clicar sobre e a tela da direita será apresentada.
Vamos clicar na última opção, complementar com a opção ".childItems" e por último clicar em OK.

Chegando lá....
Agora na Aba Activities (0), vamos clicar no ícone do lápis.

Vamos incluir um componente Copy data com a mesma configuração que realizamos no segundo caso.

Finalizada a configuração, vamos agora executar!

Sucesso! Executado conforme desejado!
Conclusão
Meu amigo, esse assunto é extremamente fantástico!
Gosto muito de trabalhar com Azure Data Factory, sinto que estou em uma grande evolução na ferramenta e fico feliz em conseguir compartilhar com você o que estou aprendendo.
Hoje trouxe para você um importante recurso que como falei acima, deve ser usado com extrema cautela, pois pode trazer alguns transtornos em seu ambiente e por favor não cometam o erro que cometi!
Apresentei apenas três formas de utilização do Dataset. Poderíamos sem dúvida nenhuma ficar o dia inteiro falando de outras formas. Mais essas já conseguem alimentar a curiosidade de vocês.
Podemos trabalhar usando arquivos JSON para parametrizar consultas, ler banco de dados entre outras.
Caso possuam alguma dúvida, estarei sempre aqui para poder ajudar.
Grande abraço e aguardo você no próximo!
Fique com Deus...
Comments