
Fala amigão! Você está acompanhando nossa imersão no Azure Data Factory? Está gostando?? Caso não esteja acompanhando e esse seja o seu primeiro post, deixo abaixo o link dos outros dois para que você possa nos acompanhar.
No post anterior abordamos os componentes do Azure Data Factory. Ele post serviu como um overview rico em detalhes. Podemos até dizer que foi maçante pois tratou apenas da parte teórica, é chato mais é um mal necessário.
Hoje a abordagem será mais hands on. Montei um roteiro de como iremos conduzir.
1º - Definir os dados que iremos trabalhar.
Como sempre abordo nesse Blob, gosto muito de usar os dados da Justiça Eleitoral
2º - Em seguida, caso não possua uma conta no Azure Storage Accout, abordaremos a sua criação pois o Blob será o nosso repositório de dados
Caso você não tenha criado ainda uma conta no Azure, deixo abaixo dois links do nosso blog onde detalho como que pode ser feita essa criação.
3º - Por fim, começaremos a criação do nosso mecanismo de cópia dos dados.
Esse último passo vamos fazer juntos! Respira, levanta da cadeira, faça um alongamento, beba uma água e não esqueça de pegar uma caneca de café!
Vou explicando bem devagar e caso fique alguma dúvida, peço que deixe um comentário.
Prontos? Valendo!
Ao realizar o seu login no Azure Data Factory, você será redirecionado para a tela abaixo. Vamos analisar a a imagem abaixo?
Para dar o pontapé inicial, que tal seguir os passos a seguir? A hora é essa. Vamos clicar no ícone da casinha (1) e em seguida, vamos clicar em Ingest (2). Acompanha comigo.

Feito isso, partiu próxima tela!
(1) - Selecionar Built-in copy task;
(2) - Selecionar Run once now (Processo é executado no final).
Uma breve descrição sobre as demais opções.
Schedule - Você cria todo o processo de cópia de dados porém no final cria um agendamento para sua execução;
Tumbing windows - Você cria todo o processo de cópia de dados porém ele é executado mediante um ação.

Conforme observamos na tela acima, o passo seguinte será a configuração da origem do nosso dado (Source).
Nesse exemplo vamos trabalhar com o seguinte cenário.
Origem - Copiar um arquivo do tipo csv de um servidor On Premise;
Destino - Gravar esse arquivo no Blob.
Observe como que irá ficar.
Configuração do Source (Origem)
Vamos começar a configuração do Source. Procurei detalhar ao máximo todos passos, basta segui-los.
(1) Selecione o tipo do dado da sua origem;
(2) Selecione a forma de conexão;
(3) Caso exista mais de uma opção, uma lista será carregada conforme imagem abaixo.
Conforme mencionado acima, vamos trabalhar com um arquivo csv.

Quando falamos em tipos de dados que podemos carregar, existe uma lista enorme de possibilidades. Analise a imagem abaixo.

Feito isso, basta clicar em NEXT. O passo seguinte será a criação de nosso Linked Service, ou seja, a forma de conexão com a nossa fonte de dados. É bem simples, acompanhe comigo.
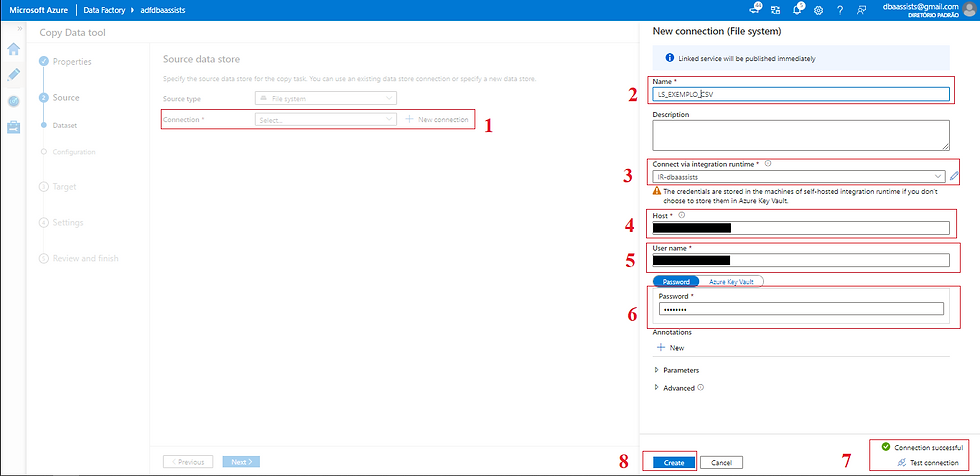
(1) Clicar em New Connection;
(2) Informar um nome para o nosso Linked Service;
(3) Como vamos trabalhar com um arquivo que está em um servidor on premise, precisarei selecionar a minha IR;
(4) Informar o diretório que está o arquivo;
(5) Informar a conta de acesso ao servidor;
(6) Informar a senha da conta;
(7) Clicar em Test Connection para poder validar a conexão;
(8) Clicar em CREATE.
Após a definição das informações do Linked Service, vamos para a configuração do DataSet.
(1) Como em meu exemplo informei que a origem é um arquivo, existe a necessidade de especificar o seu formato, podendo ser do tipo Text, Avro, JSON, ORC ou Parquet;
(2) Definir a delimitação (existe uma lista de opções);
(3) Definir se a primeira linha do arquivo irá possuir o cabeçalho;
(4) Definir o encoding (codificação) do arquivo;
(5) Visualizar uma amostra dos dados (Preview data);
(6) Concluir, clicar em NEXT.

Configuração do Target(Destino)
Hora de relaxar, respirar um pouco, beber uma água e um café! Fala comigo meu amigo, o que está achando até aqui?
Completamos aqui 50% da nossa atividade, o próximo passo é realizar a configuração do Target (Destino).
Será bem parecido com a configuração do Source, acompanha comigo.
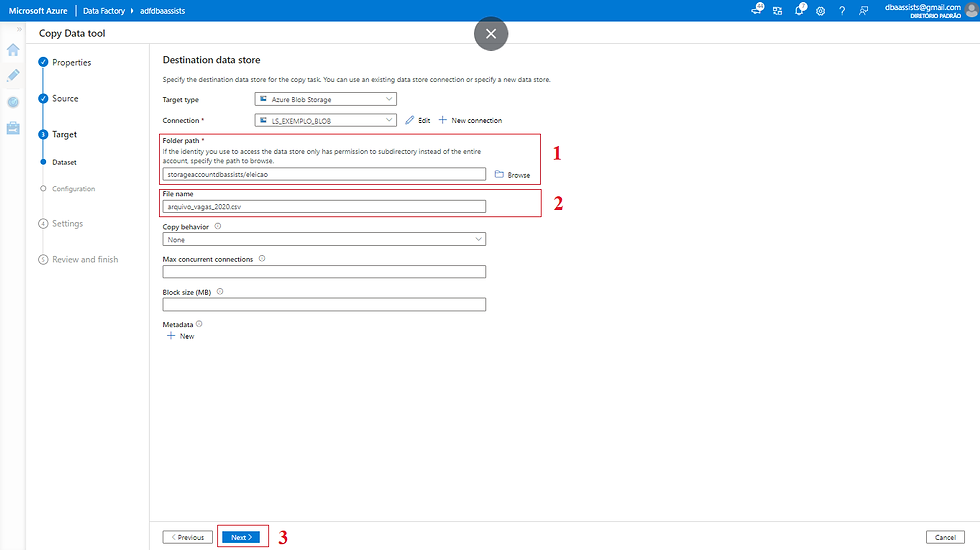
(1) Definir o tipo do destino (Target), em nosso exemplo, a nossa origem é um arquivo;
(2) Clicar em New Connection para criar o Linked Service;
(3) Informar um nome para o nosso Linked Service;
(4) Não vamos precisar de um IR pois o arquivo será gravado dentro do Blob;
(5) Autenticação será por meio de Account Key.
Quando selecionamos essa opção, o Azure Data Factory realiza a conexão através da connection string o que pode ser feito também através do Azure Key Vault;
(6) Sobre o método de autenticação usaremos o From Azure Subscription.
Quando selecionamos esse método, o Azure Data Factory irá carregar essas informações através da conta em que você está logado, caso tenha selecionado Enter manually, você precisa informar no passos seguintes o nome da Azure Storage Account e a Storage account key;
(7) Como escolhemos From Azure subscription, nesse passo vamos selecionar a subscription;
(8) Informar a Storage account name;
(9) Clicar em Text Connection, para realizar um teste em nossa conexão;
(10) Clicar em CREATE.

Nessa próxima tela, vamos descrever as informações referente ao local dentro do Blob em que o arquivo será gravado.
(1) Definir o diretório que será gravado, não se preocupe, caso o diretório informado não exista em seu Blob, ele será criado durante o processo;
(2) Definir o nome/formato (extensão) do arquivo;
(3) Concluir a configuração, clique em NEXT.
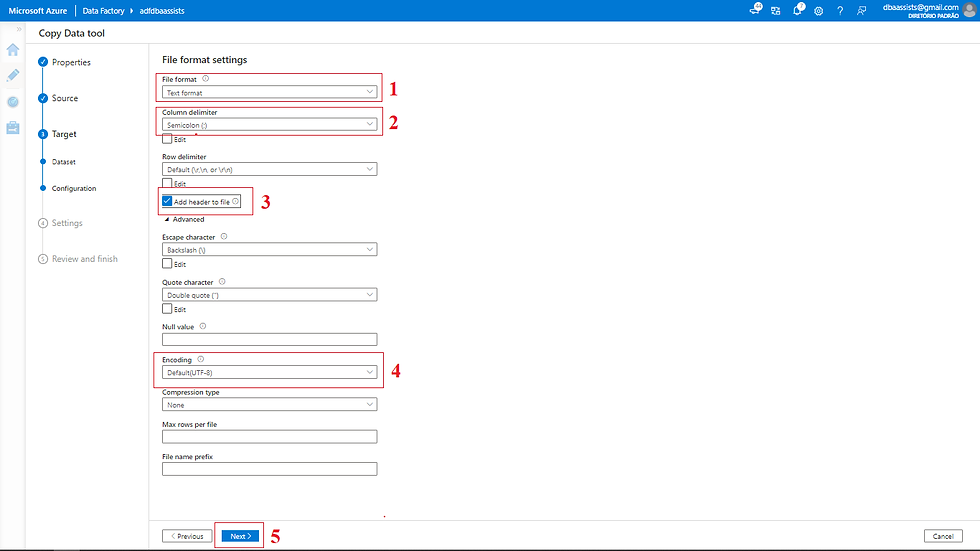
Da mesma forma que fizemos para o Source, vamos definir algumas informações para o arquivo que será carregado no Blob.
(1) Como em meu exemplo informei que o destino será um arquivo, existe a necessidade de especificar o seu formato, podendo ser do tipo Text, Avro, JSON, ORC ou Parquet;
(2) Definir a sua delimitação (existe uma lista de opções);
(3) Definir se a primeira linha do arquivo irá possuir o cabeçalho;
(4) Definir o encoding (codificação) do arquivo;
(5) Concluir, clicar em NEXT
Concluída a configuração do Source e do Target, vamos finalizar informações do nosso fluxo.
(1) Nome para a nossa Pipeline;
(2) Em caso de falha, podemos definir uma rotina de log;
(3) Definir nesse passo onde o arquivo será gravado;
(4) Definir o armazenamento temporário no Blob (essa opção é usada principalmente para carregamento no Azure Synapse Analytics e ocorre por meio do PolyBase);
(5) Tudo OK, clicar em NEXT.

Nessa próxima tela, é apresentando um overview antes de iniciar a criação.
Ela apresenta de forma simplificada, tudo que foi feito nos passos anteriores.
(1) Nome da Pipeline*;
(2) Nome da conexão que será usada no Source;
(3) Nome do DataSet do Source**;
(4) Encoding (codificação) usada no Source;
(5) Informação de que a primeira linha do arquivo é o cabeçalho;
(6) Nome do arquivo que será carregado para o Blob;
(7) Diretório de origem desse arquivo;
(8) Nome da conexão que será usada no Target;
(9) Nome do DataSet do Target**.
Observação:
Em ambos os casos com * e ** é possível realizar a alteração do nome;
No caso ** o nome é informado de forma automática pelo Azure Data Factory;
Para editar, basta clicar no botão Edit.
Estando tudo OK, basta clicar em NEXT.

No próximo passo será apresentado como que ficou o nosso fluxo.

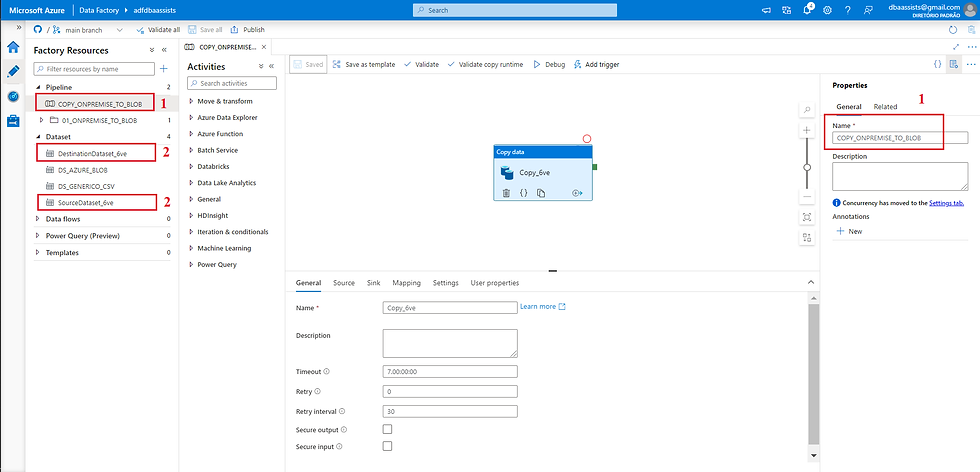
Concluída a criação, conseguimos visualizar os objetos criados.
Vamos visualizar a informação na aba Author.
(1) Nome da Pipeline;
(2) Nome dos DataSets criados.
Na tela abaixo conseguimos identificar os Linked Services criados.
(1) Listar Linked Services;
(2) Linked Services do Source e Target.

Na tela abaixo o fluxo do dado.
(1) Fluxo da origem (File system onpremise) ao destino (Blob);
(2) Dado carregado da origem (tamanho (Data Read), quantidade de arquivos (files read), quantidade de linhas (rows read));
(3) Tempo gasto (copy duration);
(4) Dado carregado no destino (tamanho (Data written), quantidade de arquivos (files written), quantidade de linhas (rows written));

Sucesso! ✅🥳 Nosso pipeline foi executado com sucesso.
Vamos agora acessar nosso Blob e verificar o arquivo carregado.
(1) Storage Account;
(2) Arquivo carregado.


Conclusão
Neste post, o nosso foco foi direcionado para o processo de copia de dados de um servidor on premise para um Blob, usando o processo de Copy Data.
A funcionalidade Copy Data no Azure Data Factory é bem semelhante ao processo de Import and Export do SQL Server, quem já trabalhou com o SQL Server sabe do que estou falando.
Sua principal função é transferir uma informação de um lugar para o outro, simples assim.
Nesse post consegui fazer uma abordagem rica em detalhes, explicando todos os passos para que você consiga ter um primeiro contato com o Azure Data Factoy.
Em nossos próximos passos da nossa jornada Desbravando o Azure Data Factory, vamos focar na utilização do Azure Key Vault, o famoso cofre de senhas do Azure, focar na criação de Pipelines utilizando Linked Services e DataSets totalmente parametrizados, explicar quais as vantagens/desvantagens.
Peço que venham preparados, pois tem muito assunto para abordar. Encontro você no próximo.
Grande abraço e fique com Deus!
Material de excelente qualidade, muito bem explicado passa a passo.