


Nesse tópico, vamos fazer uma abordagem aprofundada em um objeto muito útil e importante dentro de um banco de dados, esse objeto recebe o nome de Tabela ou no inglês Table, como queiram falar! Vamos lá...
1. Tabelas ou Tables
Vamos tentar responder as perguntas abaixo!
Tabelas ou tables, o que são? Para que servem?
Para a primeira pergunta a resposta é bem simples, Tabelas são estruturas ou objetos em um banco de dados! E para que servem? Simples também, possuem um único objetivo, armazenar dados! Corrijam se estiver errado!
Esse é um assunto muito importante e bacana de comentar, bora lá!
Colocar tudo sobre tabelas em um único post é covardia, então vamos dividir para conquistar e dividir em três blocos básico, intermediário e avançado. Confesso que não faço ideia do que é básico, intermediário e avançado, mais vou dividir conforme listado a seguir.
Qual primeiro passo que deve ser seguido antes de criar uma tabela; (criação do banco de dados (via script ou não), o que quer armazenar);
Explicar a estrutura de uma tabela; (schema, colunas, datatypes, identity, índices, relacionamentos, default value e unique value, constraints, nulabilidade, colunas derivadas, compressão de dados);
Permissões;
Bora lá então começar pelo inicio, vamos definir nossa primeira tabela? Porém para que isso ocorra, vamos precisar responder a primeira pergunta. O que pretendemos armazenar em nossa tabela? Conseguindo responder essa pergunta, a segunda ficou fácil, qual será o nome da nossa tabela?
Em sua grande maioria, um caso complementa o outro. Por exemplo, "vamos precisar armazenar os dados de nossos funcionários!", então a nossa tabela recebera o nome de "Funcionario" ou "DadosFuncionario", sempre buscando um qualificar o outro.
Atenção aqui! O nome das tabelas podem ter até 128 caracteres, não esqueçam disso!
Outras informações importantes:
Os nomes de tabela devem iniciar com um caractere alfabético, mas também podem conter sublinhas (_), símbolos de @, sinais de libra (#) e numerais;
Os nomes de tabelas devem ser únicos para cada schema (ainda vamos explicar o que é um schema, apenas um spoiler!) dentro de um banco de dados;
Diferentes esquemas podem conter tabelas com o mesmo nome;
Cada tabela pode ter até 1.024 colunas;
Os nomes de colunas seguem as mesmas regras de atribuição de nomes das tabelas e devem ser únicas, dentro de uma tabela, porém em tabelas diferentes você pode criar com o mesmo nome.
Boas Práticas! Quando falamos em boas práticas, falamos em padrões internacionais, não estamos falando que caso não sigam estejam errados, porém são costumes que toda comunidade assume. Conforme citado acima, o nome da tabela e de suas colunas podem conter diversos caracteres inclusive espaço. Caso venha incluir o espaço no nome, você precisará usar colchetes “[Nome Tabela]” ou “[Nome Coluna]”. Lembre-se, isso não é uma boa prática, porém também não está errado! Podendo encontrar em qualquer lugar, infelizmente!
Até aqui respondemos apenas as algumas perguntas, "o que são tabelas?", "para que servem?", "o que pretendemos armazenar?" e "qual será o nome da nossa tabela?". No próximo passo, vamos colocar a mão na massa. Bora criar essa nossa tabela "Funcionário".
Porém, para que uma tabela exista, precisamos criar um banco de dados, pois é onde ela será armazenada. E como criar esse banco de dados? Vamos para o próximo item...
Criação do Banco de Dados
Para poder iniciar de forma prática a criação de nossas tabelas, no Microsoft SQL Server, vamos precisar realizar a criação de um banco de dados, pois o Microsoft SQL Server utiliza essa estrutura única para armazenar seus objetos (Banco de Dados + Schema + Objetos).
Antes de partir para criação do nosso primeiro banco de dados, vamos falar um pouco sobre um outro objeto do banco de dados chamado Schema.
O que é um Schema?
Schema é uma estrutura usada para realizar o agrupamento de objetos, podendo servir até para separar objetos de varias partes dentro de um sistema. Exemplo: Pense em um sistema ERP, onde possuímos módulos de RH, Financeiro e Contabilidade. Podemos com a utilização de Schemas, separar tabelas usadas em cada módulo conforme abaixo.
Tabela de Funcionario: rh.Funcionario
Tabela de Fornecedor: financeiro.Fornecedor
Tabela de Lançamentos Contábeis: contabilidade.LancamentoContabeis
Então com isso, sempre que criarmos uma tabela ela irá possuir a seguinte estrutura
CREATE TABLE [Schema].[Nome Tabela]
Para um maior aprofundamento sobre SCHEMAS, segue o link abaixo.

Link criação schema: https://docs.microsoft.com/pt-br/sql/t-sql/statements/create-schema-transact-sql?view=sql-server-ver15
Bora avançar meu povo...Vamos criar nosso banco de dados! Para isso, vamos usar o SQL Server Management Studio ou SSMS que instalamos no post anterior, caso não tenha visto, acesse o link abaixo.
Instalação do Microsoft SQL Server Express e SQL Server Management Studio: https://dbagabriel.wixsite.com/dba-assists/post/navrhn%C4%9Bte-si-%C3%BAchvatn%C3%BD-blog
Aqui uma dica importante! Quando realizei o login no SSMS, observei que quando instalei, ela ocorreu na versão em português, caso queiram trocar o idioma, segue um link de ajuda.
Link para alterar idioma do SSMS: https://jvilar.wordpress.com/2016/07/03/como-mudar-o-idioma-do-sql-server-management-studio/
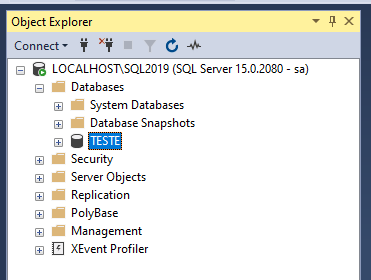
No SQL Server Management Studio (SSMS) vamos criar um banco de TESTE, esse será o seu nome. Para ser mais ágil e ganharmos tempo, sua criação será feita da forma simples, rápida e sem entrar em detalhes (mais voltaremos a falar desse assunto). Para criação, vamos seguir esses passos:
1. Após iniciar o SSMS, conecte-se à instância de servidor onde iremos criar o nosso banco de dados. Em alguns ambiente, precisaríamos ter permissão para essa ação, mais nesse exemplo não iremos nos preocupar com essa validação de permissão, trabalharemos como se o usuário possuísse essa permissão associada ao seu usuário;




Conforme imagem da esquerda, para criar o Database, no Object Explorer, clique com o botão direito do mouse sobre o nó Databases e seguida em "New Database...". Feito isso, a imagem da direita será aberta, preencha o campo "Database name:" com o nome do banco de dadosm no nosso caso coloque TESTE, e clique em OK.





Pronto, banco de dados criado!
Agora de uma forma bem mais rápida! Clique em em New Query, execute os comando abaixo:
CREATE DATABASE TESTE;
Simples assim! Feito isso, conseguimos ver as duas formas possíveis de criar um banco de dados, uma utilizando a forma gráfica e outra por script. No último passo, usamos a forma mais simples, porém não utilize dessa forma caso estejam fazendo a criação em um ambiente de produção.
Podemos também criar via script de uma forma mais detalhada. Caso tenha curiosidade, deixo aqui um link de consulta.
Link CREATE DATABASE - https://docs.microsoft.com/pt-br/sql/t-sql/statements/create-database-transact-sql?view=sql-server-ver15&tabs=sqlpool

Depois dos passos acima, vamos voltar no processo de criação do nosso banco de dados e fazer alguns comentários.
Muitos pontos importantes que não podemos deixar passar batido, por mais que não seja o foco do nosso estudo, mais conhecimento nunca é demais!
Bora galera!!!!

Conforme imagem acima, vamos comentar sobre as opções:
Logical Name - Quando o banco de dados é criado, dois arquivos são gerados, um será usado para armazenamento dos dados (outros arquivos podem ser adicionados depois) e o outro para as instruções realizadas e que será base para uma possível restauração;
File Type - Ajuda a identifica exatamente o tipo de arquivo, Dados ou Log;
Filegroup - São coleções nomeadas de arquivos e são usados para simplificar o posicionamento de dados;
Initial Size (MB) - Determina o tamanho inicial do seu banco de dados;
Autogrowth/Masize - Determina a forma de crescimento de seu arquivo de dados. Esse crescimento pode ser determinado megabytes ou em percentual além da forma de crescimento, também podemos indicar que ele poderá crescer de uma forma ilimitada, ou seja, até o espaço de disco terminar ou você pode especificar um limite máximo de tamanho que ele pode atingir;
Path - Por default ele assume sempre o caminho definido no momento da instalação do SGBD, porém nada impede você de escolher um diretório, e em um futuro também pode movimenta-lo para qualquer lugar;
File Name - Trata-se do nome do arquivo que será dado no momento da sua criação. Por default, ele sempre coloca o nome do arquivo como o nome dado ao banco de dados, caso seja o arquivo principal de dados, no nosso caso, irá assumir o nome "TESTE.mdf", para o de Log "TESTE.ldf" e caso venha a ser adicionado algum arquivo secundário, o mesmo receberá o nome de "TESTE.ndf";
Deixo abaixo dois links para consultas com maiores detalhes.
Link Arquivos e grupos de arquivos do banco de dado: https://docs.microsoft.com/pt-br/sql/relational-databases/databases/database-files-and-filegroups?view=sql-server-ver15
Link CREATE DATABASE - https://docs.microsoft.com/pt-br/sql/t-sql/statements/create-database-transact-sql?view=sql-server-ver15&tabs=sqlpool

E para imagem acima, deixo os links para consulta:
Link Modos de Recuperação: https://docs.microsoft.com/pt-br/sql/relational-databases/backup-restore/recovery-models-sql-server?view=sql-server-ver15
Link Auto Create/Update Statistics - https://docs.microsoft.com/pt-br/sql/relational-databases/statistics/statistics?view=sql-server-ver15
Link Auto Close - https://docs.microsoft.com/pt-br/sql/relational-databases/policy-based-management/set-the-auto-close-database-option-to-off?view=sql-server-ver15
Link Auto Shrink - https://docs.microsoft.com/pt-br/troubleshoot/sql/admin/considerations-autogrow-autoshrink
Link Alter Database - https://docs.microsoft.com/pt-br/sql/t-sql/statements/alter-database-transact-sql-set-options?view=sql-server-ver15
Pois bem, agora que estamos com nosso banco de dados "TESTE" criado, vamos entrar definitivamente no nosso assunto e tentar esmiuçar o assunto principal desse post, Tabelas!
Criação das Tabelas

Vamos ao que interessa, podemos enfim criar nossas tabelas!
Hora de aprender um pouco mais...simbora gente!
Voltamos ao SQL Server Management Studio ou SSMS e seguindo os passos abaixo, vamos criar nossa primeira tabela:
Após iniciar o SSMS, conecte-se à instância de servidor que contém o banco de dados. Em alguns ambiente, precisaríamos ter permissão para essa ação, mais nesse exemplo não iremos nos preocupar com essa validação de permissão, trabalharemos como se o usuário possuísse essa permissão associada ao seu usuário;
Para selecionar o Database, no Object Explorer, expanda o nó Databases e em seguida selecione um banco de dados. Descendo mais um nível, expanda novamente a visão para mostrar os nós dos seus recursos.
Para criar uma nova tabela, clique com o botão direito do mouse no nó Tabelas ou Tables e então selecione New -> Tables. Em seguida, acesse o Table Designer no SQL Server Management Studio.

Ao clicar em "Table...", a tela abaixo será apresentada para definição da estrutura da nossa tabela.


Nossa, quanta informação! Vamos para explicação! Na coluna destacada de "Column Name", especificamos o nome das colunas que irão compor nossa tabela, na coluna "Data Type", é onde especificamos o tipo do dado que a coluna irá receber (Não se preocupe nesse momento, pois Data Type é o assunto do nosso próximo post) e na coluna "Allow Nulls", é onde definimos se uma coluna pode ou não possuir valor quando um registro (tupla ou linha) for inserida em nossa tabela.
Feito isso, basta clicar no "X" para concluir a etapa de definição das colunas e partir para nomear o nosso objeto ou tabela.
Após isso, a tela abaixo será apresentada e o nome da tabela deverá ser informado.

Clicando em OK, nossa tabela é criada.
Para visualizar a tabela criada, clique em cima do banco de dados (no nosso caso TESTE) e pressione o botão de atualizar em destaque na imagem e a nossa tabela "Funcionario" será apresentada. Para visualizar a sua estrutura, ao lado do seu nome basta clicar no botão "+" para expandir sua estrutura e em seguida clique no botão "+" em "Columns" ou caso o seu esteja em português, "Colunas", pronto, nossa primeira tabela foi criada!.

Agora vamos ver outra forma de criar a nossa tabela usando agora o comando "CREATE TABLE" via linha de comando.
CREATE TABLE dbo.Funcionario
(
IdFuncionario int NULL,
NomFuncionario varchar(100) NULL,
DataNascimento date NULL,
DscSexo char(1) NULL
)O script acima para criação de uma tabela ele sempre terá esse comportamento.
Toda instrução de criação de tabelas segue o mesmo padrão conforme a instrução a seguir:
Sintaxe do comando
CREATE TABLE [NOME SCHEMA].[NOME TABELA]
(
DEFINIÇÃO DOS CAMPO
)
Quando vamos definir quais campos que farão parte da nossa tabela, três perguntas primordiais não podem deixar de ser respondidas:
1. [QUAL O NOME DA COLUNA?]
2. [QUAL SERÁ O TIPO DE DADO ARMAZENADO?]
3. [PODERÁ ACEITAR VALORES NULOS?]
No nosso exemplo, a nossa tabela "Funcionario" deverá conter as seguintes informações:

Uma coluna pra identificar o funcionário através de um código, deverá aceitar apenas valores numérico e não pode ficar em branco;
Uma coluna para identificar o nome do funcionário, deverá aceitar texto e não pode ficar em branco;
Uma coluna para identificar a data de nascimento, deverá aceitar apenas data e não pode ficar em branco;
E uma coluna para identificar o sexo do funcionário com a seguinte regra, se for masculino, deverá ter M e se for feminino F e não pode ficar em branco.
Com as informações acima, ficou fácil criar a nossa tabela. Vou criar com a nomenclatura abaixo, mais você pode criar a sua própria tabela, desde que ela atenda aos requisitos. Vamos ver como que ficou o meu código.
CREATE TABLE dbo.Funcionario(
IdFuncionario int NOT NULL,
NomFuncionario varchar(100) NOT NULL,
DataNascimento date NOT NULL,
DscSexo char(1) NOT NULL
)
O script acima ficou diferente em relação ao anterior, não se preocupe! Caso você tenha criado a tabela com o outro script, peço que execute o script abaixo de DROP TABLE (Eu sei, ainda não falei sobre esse comando, mais guarde ai o primeiro spoiler) antes de criar a tabela.
Vamos usar esse comando outras vezes assim que evoluímos nos artigos, ele é bem simples e vocês vão entender!

DROP TABLE dbo.Funcionario;
Link DROP TABLE: https://docs.microsoft.com/pt-br/sql/t-sql/statements/drop-table-transact-sql?view=sql-server-ver15
Como usamos o Table Designer, destaquei alguns pontos que podem ter geradas algumas duvidas/perguntas:
Já falamos sobre "Column Name", "Data Type" e "Allows Nulls", agora vamos falar sobre o que seria um default value or binding, uma computed column specification e identity specification.
Bora então começar falando sobre Computed Column!
O que é uma Computed Column? Para que serve?

É um recurso que foi criado para que seja possível a criação de colunas que são calculadas (quando falo calculadas, não é na forma literal matemática) baseada sempre em uma fórmula (combinando colunas da mesma tabela).
No momento da sua criação ela pode ser definida como sendo persistida ou não. E qual a diferença? Quando ela for persistida, significa que o resultado da fórmula é armazenada dentro da tabela e quando não for, significa que será montada/calculada em tempo de execução.
Teoria exposta, vamos a prática!

Primeiro vamos usar o comando DROP TABLE para eliminar essa tabela (Olha o spoiler ai outra vez!);
Depois vamos editar nossa tabela para criar uma coluna para "armazenar" a idade do funcionário. Essa coluna receberá o nome NumIdadePaciente;
Após criada a tabela com a computed column, vamos inserir um registro para verificar qual o valor será apresentado (Olha ai o segundo e terceiro spoiler).
Vamos ver como que ficaram as instruções:
-- Elimina Tabela Funcionario
DROP TABLE dbo.Funcionario;
-- Cria Tabela Funcionario
CREATE TABLE dbo.Funcionario(
IdFuncionario int NOT NULL,
NomFuncionario varchar(100) NOT NULL,
DataNascimento date NOT NULL,
DscSexo char(1) NOT NULL,
NumIdadeFuncionario AS DATEDIFF(YEAR,DataNascimento,GETDATE())
);Conforme mencionado acima, as colunas calculadas ou computed column, são formadas baseadas em uma fórmula. Para esse nosso exemplo, sempre que consultados os dados da tabela, a idade deve ser calculada.
Vamos usar nesse caso duas funções nativas do Microsoft SQL Server DATEDIFF() essa função realiza o uma operação matemática entre datas e a GETDATE() gera a data no momento da execução (Olha mais dois spoilers!) combinado com a coluna DataNascimento para realizar o cálculo.
Comando INSERT, usado para incluir registros em uma tabela (Segundo spoiler, toda hora tem!)
Vamos ver como que fica a instrução:
-- Insere dados na tabela Funcionario
INSERT INTO dbo.Funcionario
(IdFuncionario,NomFuncionario, DataNascimento,DscSexo)
VALUES
(1, 'WANDERLEY QUINTELLA','1940-01-01','M');Agora vamos consultar nossa tabela! Para isso vamos usar o comando SELECT (preciso falar que temos mais um spoiler? Estamos demais!).

Reparem que nenhum valor foi informado durante a instrução de INSERT para coluna NumIdadeFuncionario e quando realizamos a consulta através do comando SELECT, o valor é retornado.
Isso ocorre exatamente devido a função DATEDIFF(YEAR, DataNascimento , GETDATE()) que foi colocada na definição da coluna NumIdadeFuncionario.
NumIdadeFuncionario AS DATEDIFF(YEAR, DataNascimento , GETDATE())Lendo essa função, ela utiliza a coluna DataNascimento para subtrair da data do momento da consulta, informação retornada através da função GETDATE() e essa função foi definida para retorna o seu resultado em ANOS, reparem a definição YEAR.
Para finalizar esse ponto, lembra que mencionei no início a seguinte frase "No momento da sua criação ela pode ser definida como sendo persistida ou não. E qual a diferença? Quando ela for persistida, significa que o resultado da fórmula é armazenada dentro da tabela e quando não for, significa que será montada em tempo de execução.", e como faz isso acontecer? Para que um valor seja persistido em disco, bastar no momento da criação da coluna informar no final da linha a palavra PERSISTED, caso não seja informado, por default, o SGBD entenderá que o valor não é pra ser persistido.
Atenção ao uso de função determinísticas e não determinísticas quando for definir que uma computed column deverá ser persistida em banco. Maiores informações no link abaixo.
Link Funções Determinísticas e Não Determinísticas: https://docs.microsoft.com/en-us/sql/relational-databases/user-defined-functions/deterministic-and-nondeterministic-functions?redirectedfrom=MSDN&view=sql-server-ver15
Link Computed Column: https://docs.microsoft.com/pt-br/sql/relational-databases/tables/specify-computed-columns-in-a-table?view=sql-server-ver15
Bora avança para o próximo, Identity, mais o que é isso? É de comer?
O que é um Identity? Para que serve?
O argumento IDENTITY é usado no momento da criação de uma tabela e tem como finalidade a criação de um identificador sequencial, sequência esse que também é determinada na criação da tabela e é muito usado para colunas que são definidas como Primary Key e também é chamadas de coluna burras e somente pode existir uma por tabela.
Vamos aplicar isso em nossa tabela, porém não podemos deixar de eliminar caso tenha sido criada!
-- Elimina a Tabela Funcionario
DROP TABLE dbo.Funcionario;
-- Cria a tabela Funcionario
CREATE TABLE dbo.Funcionario(
IdFuncionario int NOT NULL IDENTITY(1,1),
NomFuncionario varchar(100) NOT NULL,
DataNascimento date NOT NULL,
DscSexo char(1) NOT NULL,
NumIdadeFuncionario AS DATEDIFF(YEAR,DataNascimento,GETDATE())
);Após a criação da tabela, vamos inserir novamente nosso registro. Reparem no script abaixo que o valor da coluna IdFuncionario não é mais informado. Isso se faz porque o campo agora e auto incremental.
INSERT INTO dbo.Funcionario (NomFuncionario,DataNascimento,DscSexo)
VALUES ('WANDERLEY QUINTELLA','1940-01-01','M');Mesmo sendo auto incremental, existe a possibilidade de inserir um valor para uma coluna Identity. Conforme script abaixo.
set identity_insert dbo.Funcionario on
insert into dbo.Funcionario (IdFuncionario,NomFuncionario,DataNascimento,DscSexo)
VALUES (20, 'VANILCE LACERDA','1945-03-09','F')
set identity_insert dbo.Funcionario offVamos ver como que ficou.

E para finalizar o assunto Identity, existe um comando que ele é usado quando precisamos ajustar o valor da Identity. Para essa ação, usando a instrução DBCC CHECKIDENT, conforme abaixo.
Link DBCC CHECKIDENT: https://docs.microsoft.com/pt-br/sql/t-sql/database-console-commands/dbcc-checkident-transact-sql?view=sql-server-ver15

Como estamos falando em redefinição de valores para campos do tipo identity. Existe uma instrução dentro do banco de dados chamado TRUNCATE TABLE que quando executada para eliminar registros de uma tabela e se essa tabela possuir uma coluna do tipo identity, esse valor é reiniciado sem a necessidade de executar a instrução DBCC CHECKIDENT.
Esse comportamento não é visto quando usando uma outra instrução de eliminação de registros chamada de DELETE. Quando você executa o DELETE, sua tabela fica com um GAP entre um registro e outro.
Vamos aos exemplos!
- Instrução TRUNCATE TABLE
-- Sintaxe comando Truncate Table
TRUNCATE TABLE < nome tabela >;- Instrução DELETE
-- Sintaxe comando Truncate Table
DELETE FROM < nome tabela >;Pronto, mais um finalizado! Agora vamos falar sobre default values!
Para maiores detalhes, abaixo o link de referência da Microsoft.
O que é um default value? Para que serve?
Quando falamos em dafault value, pensamos em valores que são informados de forma automática quando não são explicitamente informados na instrução INSERT.
Vamos voltar ao nosso exemplo e criar uma coluna que irá receber o valor de uma data sempre que um registro for inserido.
-- Elimina tabela Funcionario
DROP TABLE dbo.Funcionario;
-- Cria tabela Funcionario
CREATE TABLE dbo.Funcionario(
IdFuncionario int NOT NULL IDENTITY(1,1),
NomFuncionario varchar(100) NOT NULL,
DataNascimento date NOT NULL,
DscSexo char(1) NOT NULL,
NumIdadeFuncionario AS DATEDIFF(YEAR,DataNascimento,GETDATE()),
DthInclusao DATETIME NOT NULL DEFAULT GETDATE()
);
-- Insere valores tabela Funcionario
INSERT INTO dbo.Funcionario (NomFuncionario,DataNascimento,DscSexo)
VALUES ('WANDERLEY QUINTELLA','1940-01-01','M');
-- Seleciona valores tabela Funcionario
SELECT * FROM dbo.Funcionario;
Em destaque a linha incluída onde defino um valor default para a coluna DthInclusao. Ressalto que você pode informar um registro no script de INSERT.
Finalizando! Ufa...vamos lá, estamos quase lá...
Falaremos agora de duas instruções que são usadas para alterar ou excluir uma tabela, vamos lá então!
Quando precisamos realizar a alteração de uma tabela criada, exemplo, aumente o número de caracteres, incluir ou excluir uma coluna entre outros.
Nesses casos, devemos usar a instrução ALTER TABLE, exemplo:
Alterar o tamanho da coluna “NomeFuncionario” na tabela Funcionario:
ALTER TABLE [dbo].[Funcionario] ALTER COLUMN NomeFuncionario VARCHAR(400) NULL
Incluir a coluna “CodSexo” com tamanho 1 do tipo VARCHAR.
ALTER TABLE [dbo].[Funcionario] ADD CodSexo VARCHAR(1) NULL;
Excluir a coluna “CodSexo” da tabela Funcionario:
ALTER TABLE [dbo].[Funcionario] DROP COLUMN CodSexo;
E quando precisamos realizar a exclusão de uma tabela dentro de um banco de dados, devemos usar a instrução DROP TABLE, exemplo:
DROP TABLE [dbo].[Funcionario];
Não é uma prática a criação de tabelas usando o Table Designer, essa deve ser uma prática que todos devem possuir correndo nas veias.
Quando fala-se na criação de uma tabela, uma enormidade de configurações podem ser feita, criação de chaves primárias (Primary Key) ou chaves estrangeiras (Foreign Key), definição de colunas com valor definido no momento da inserção de uma linha (ou tupla), criação de índices, inclusão de restrição de exclusividade, escolha do tipo de dado e tamanho para uma coluna (string, numeric, date) e mais um monte.
Link Alter Table: https://docs.microsoft.com/pt-br/sql/t-sql/statements/alter-table-transact-sql?view=sql-server-ver15
Nos próximos tópicos, abordaremos com mais detalhes cada um dos pontos falados acima. Bora lá!
Instruções que foram abordadas nesse tópico:
CREATE -> Use instruções CREATE para definir novas entidades. Use CREATE TABLE para adicionar uma nova tabela em um banco de dados.
ALTER -> Use as instruções ALTER para modificar a definição de entidades existentes. Use ALTER TABLE para adicionar uma nova coluna ou alterar a estrutura de uma tabela.
DROP -> Use instruções DROP para remover entidades existentes. Use DROP TABLE para remover uma tabela de um banco de dados.
O que vimos até aqui?
Pergunta complexa essa hein! Com esse tópico, foi possível entender que dentro de um banco de dados, podemos possuir alguns objetos denominados tabelas ou tables, que nos permitir fazer o armazenamento de diversos dados.
Explicamos que para uma coluna dentro de uma tabelas é possível o armazenamento de diferentes tipos de dados, textos, datas, números, uma variedade enorme que será detalhada no próximo tópico!
Além disso, passamos pela instrução identity que nos permite de forma automática a geração de valores, falamos de nulabilidade, computed column, default value e rolou um monte de spoilers.
Finalizamos falando de duas instruções, ALTER TABLE e DROP TABLE, o comando ALTER TABLE e para eliminar de forma definitiva, o comando DROP TABLE.
Para entender um pouco mais, abaixo alguns links de referência.
Links de referência:
Link CREATE TABLE: https://docs.microsoft.com/pt-br/sql/t-sql/statements/create-table-transact-sql?view=sql-server-ver15
Link ALTER TABLE: https://docs.microsoft.com/pt-br/sql/t-sql/statements/alter-table-transact-sql?view=sql-server-ver15
Link DROP TABLE: https://docs.microsoft.com/pt-br/sql/t-sql/statements/drop-table-transact-sql?view=sql-server-ver15
O que esperar do próximo tópico?
O próximo tópico será mais leve, mais vamos falar bastante. Comentaremos sobre os tipos de dados. É um capítulo que servirá como base para aprimorar o processo de criação das tabelas ou tables. Explicaremos para que serve, suas diferenças e como usá-los. Um tópico super importante, não percam!
Comments