
E ai amigão tubo bem com essa força? Pronto para uma bateria de estudos?? Ótimo! Simbora então!
Hoje quero trazer para você uma rotina muito usual de monitoramento das execuções dos seus pacotes SSIS.
Na empresa que trabalho ela agrega muito valor pois quando iniciamos o nosso dia de trabalho já possuímos conhecimento de como que foi a execução dos nosso pacotes, conseguimos avaliar se algum teve um aumento de tempo expressivo que nos leva a uma análise de performance, ou se, ele ajuda muito no nosso trabalho!
Como base desse post, vou usar o mesmo pacote que trabalhamos quando falamos do componente ForEach Loop Container então se você está acompanhando meu trabalho vai ficar muito familiarizado com esse post.
Fugindo o nosso costumo, nesse poste não vou fazer uma introdução pois ele irá alterar ao longo do nosso desenvolvimento e pode ficar um pouco confuso!
Mais se eu fosse você não perdia essa, vai ser top! Ou melhor vai ser f...
Mão a obra! Pois camarão que dorme a onda leva...
1 - Criando um Projeto no SQL Server Integration Services
Vou considerar que você não tem nenhum projeto criado no Visual Studio do SQL Server Integration Service. Um ponto bem importante desse estudo é que não irei falar como que você realiza a configuração do seu ambiente, entenderei que você já tenha feito isso em outro momento.
Para criar um projeto é bem simples. Vamos abrir o Visual Studio e seguir os próximos passos.
(1) Selecionar File;
(2) New;
(3) Project;
(4) Caso tenha um projeto criado basta clicar em Open Project.
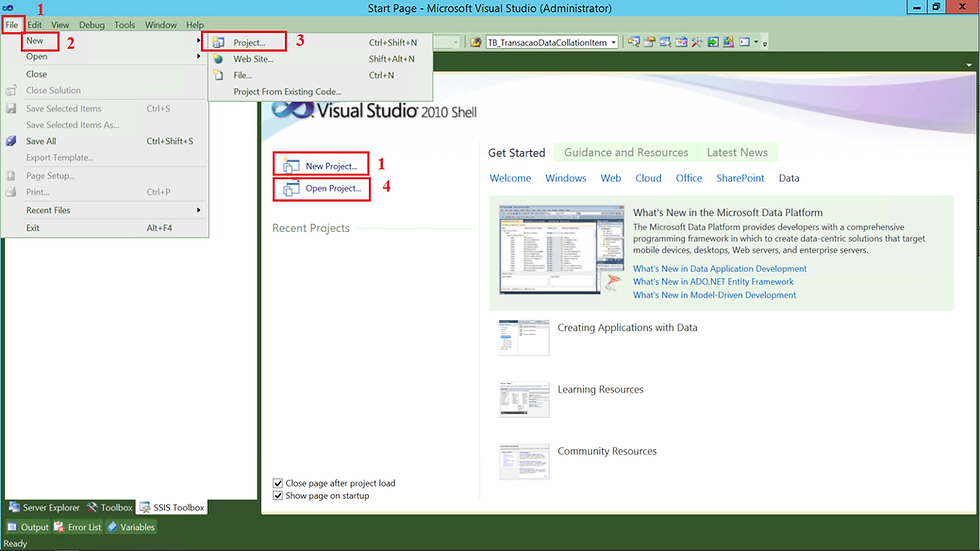
Após clicar em New Project, a tela abaixo será apresentada.
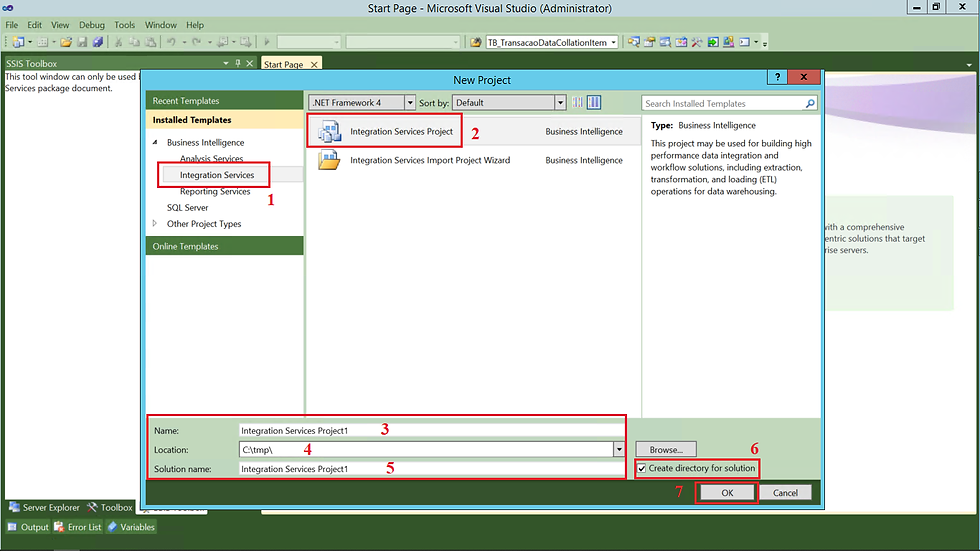
(1) Escolher Integration Services;
(2) Integration Services Project;
(3) Informar um nome para o Projeto;
(4) Definir o local (diretório) que o projeto será gerado;
(5) Informar uma nomenclatura para a sua solução;
(6) Caso queira que um diretório para o projeto seja criado basta marcar essa opção;
(7) Clicar em OK para realizar a criação;
2 - Criando nosso Pacote de ETL
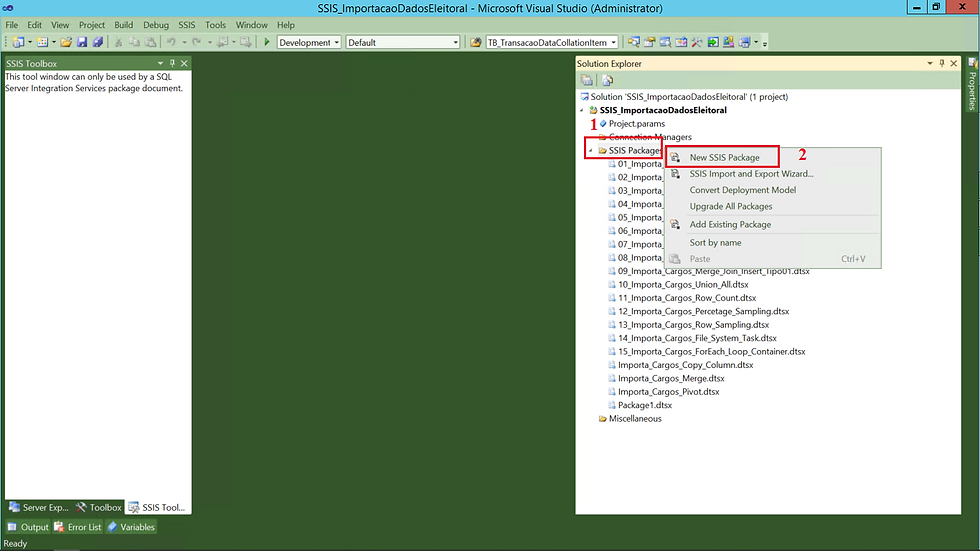
Primeiro ação será a criação de um pacote do SSIS. Essa criação é bem simples, acompanha comigo.
(1) Clicar com o botão direito do mouse sobre SSIS Package;
(2) Clicar em New SSIS Package;
Além dessa possibilidade, outras ações podem ser realizadas.
Importar um Arquivo dtsx - basta clicar em Add Existng Package;
Realizar o Upgrade dos seus pacotes - basta clicar sobre Convert Deployment Model ou Upgrade All Package;
Realizar um Import and Export - basta clicar sobre SSIS Import and Export Wizard;
Ordenar seus pacotes - basta clicar em Sort by name.
Após a criação do nosso arquivo dtsx, vamos para o desenho do nosso fluxo.
(1) Nome do arquivo dtsx;
Para alterar basta clicar sobre ele e apertar o botão F4 e em file name informar o nome do seu pacote.

Ou clicar sobre o pacote e apertar F2
(2) Aba Control Flow;
(3) Inserir um componente de Data Flow Task;
(4) Realizar duplo clique ou clicar em Data Flow.

Ao clicar em Data Flow, vamos começar a brincadeira! Dessa vez vamos fazer iguais aos filmes de Hollywood começando do final. Apresento para você como que será o resultado final desse nosso trabalho (1).


Vamos trabalhar então para produzir mais esse conteúdo.
3 - Criando as Conexões
Primeiro passo será realizar a configuração das nossas conexões.
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New Flat File Connection;

Após selecionar esse tipo de conexão, vamos partir para configuração.
(1) Informar um nome para a conexão;
(2) Primeira configuração será na aba General;
(3) Selecionar o local onde está o nosso arquivo;
(4) Configurações referente ao nosso arquivo (Se ele é delimitado ou não, se possui um qualificador de texto, se a primeira linha do arquivo contém ou não o cabeçalho das colunas etc);
(4) Clicar em OK para confirmar.

Agora vamos para outra aba.
(1) O nome que você informou na tela anterior é carregado em todas as abas seguintes, não precisa informar;
(2) Vamos configurar a aba Columns;
(3) Selecionar o delimitador de linhas;
(4) Selecionar o delimitador de colunas;
(5) Uma prévia dos dados. Observe que o cabeçalho foi carregado pois na tela anterior informamos que a primeira linha do arquivo contém o cabeçalho;
(6) Caso nenhuma configuração a mais precise ser feita, podemos concluir a configuração clicando em OK.

(1) O nome que você informou na tela anterior é carregado em todas as abas seguintes, não precisa informar;
(2) Vamos configurar a aba Advanced;
(3) Nome da colunas;
(4) Nesse passo conseguimos visualizar informações referente ao nome da coluna, datatype, tamanho, tudo isso pode ser alterado;
(5) Nesse ponto é possível incluir ou eliminar uma coluna;
(6) Caso nenhuma configuração a mais precise ser feita, podemos concluir a configuração clicando em OK.
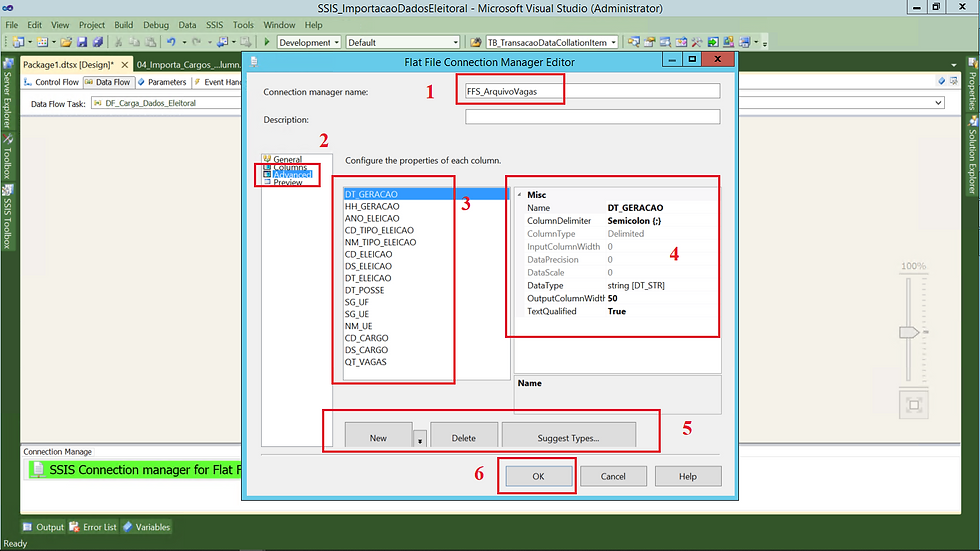
Agora vamos para o último ponto da configuração. Na aba Preview como o próprio nome diz, é uma prévia dos dados e além disso você pode também definir a quantidade de linhas que serão descartadas.
(1) O nome que você informou na tela anterior é carregado em todas as abas seguintes, não precisa informar;
(2) Vamos configurar a aba Advanced;
(3) Podemos definir a quantidade de linhas que serão descartadas;
(4) Prévia dos dados;
(5) Clicar em OK para finalizar a configuração.

Próximo passo é a configuração da conexão que será usada no Destination.
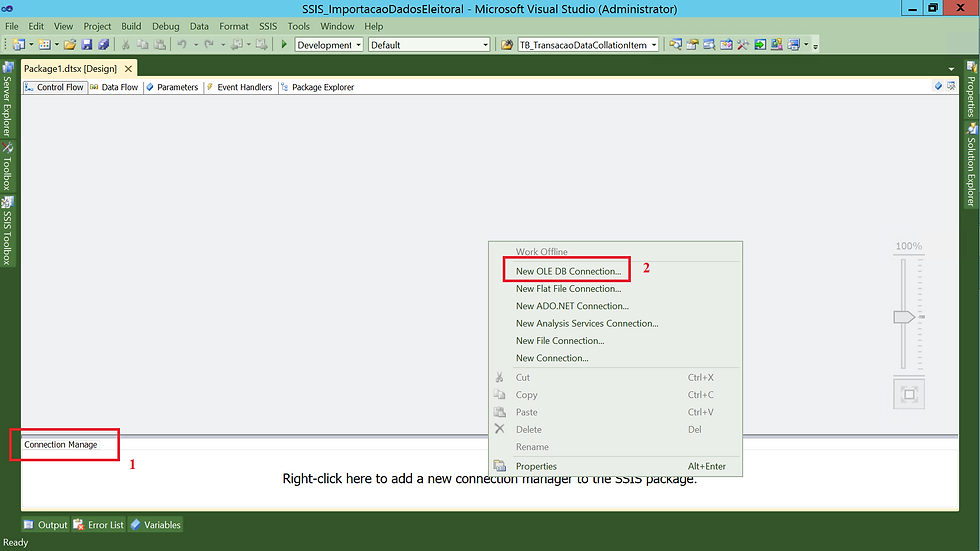
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New OLE DB Connection;

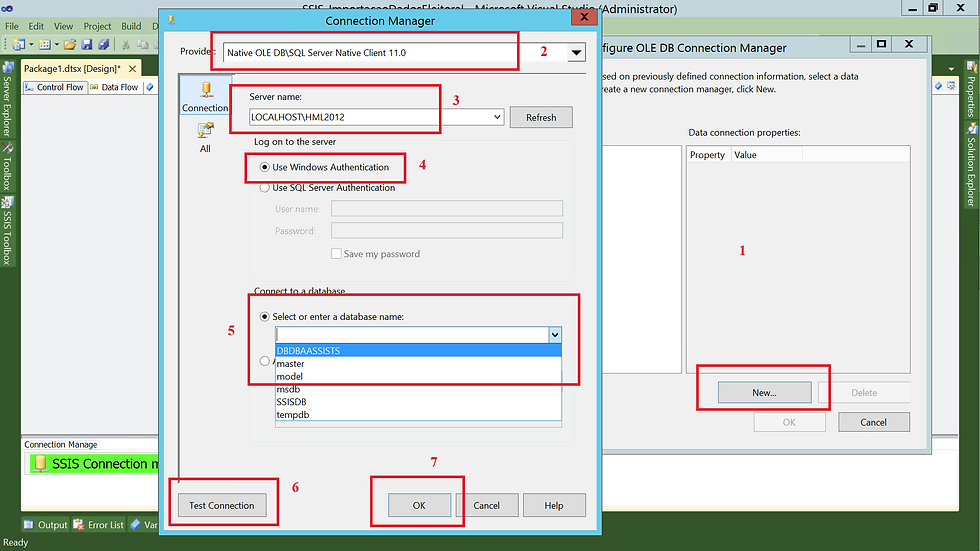
(1) Na aba Connection Manager, vamos clicar com o botão direito e selecionar OLE DB Connection Manager. Na tela que será apresentada, vamos clicar em New;
(2) Selecionar Native OLE DB\SQL Server Native Client 11.0;
(3) Informar o nome do servidor\instância;
(4) Selecionar o método de conexão;
(5) Selecionar o banco de dados. Clicando na setinha pra baixo é possível visualizar todos os bancos existentes em nosso servidor;
(6) Clicar em Test Connection para validar a conexão (Sempre comento que esse passo é desnecessário, pois ela já foi validada no passo anterior);
(7) Clicar em OK para finalizar.
3 - Criando as Conexões
Primeiro passo será realizar a configuração das nossas conexões.
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New OLE DB Connection;
(1) Na aba Connection Manager, vamos clicar com o botão direito e selecionar OLE DB Connection Manager. Na tela que será apresentada, vamos clicar em New;
(2) Selecionar Native OLE DB\SQL Server Native Client 11.0;
(3) Informar o nome do servidor\instância;
(4) Selecionar o método de conexão;
(5) Selecionar o banco de dados. Clicando na setinha pra baixo é possível visualizar todos os bancos existentes em nosso servidor;
(6) Clicar em Test Connection para validar a conexão (Sempre comento que esse passo é desnecessário, pois ela já foi validada no passo anterior);
(7) Clicar em OK para finalizar.

(1) Aba Connection Manage;
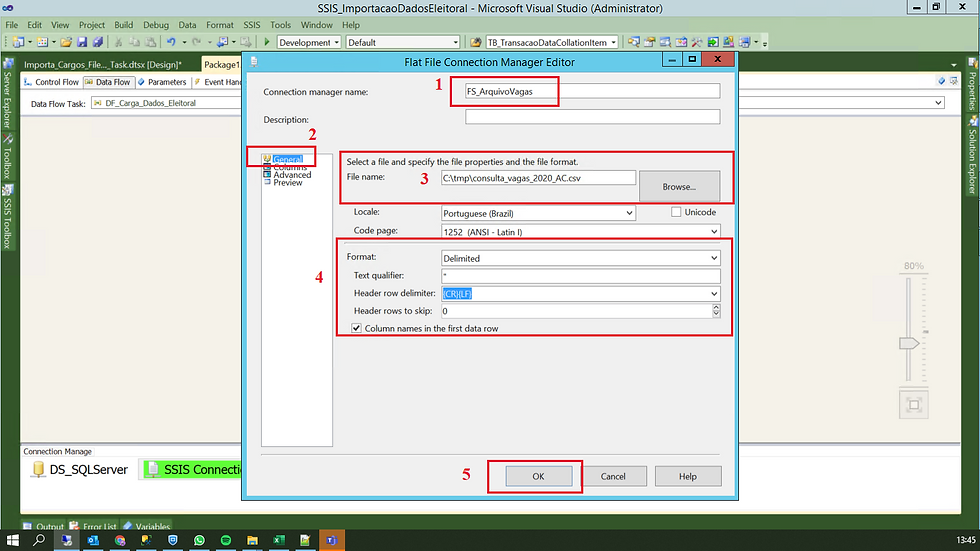
(2) Clicar com o botão direito do mouse e escolher New Flat File Connection;

Após selecionar esse tipo de conexão, vamos partir para configuração.
(1) Informar um nome para a conexão;
(2) Primeira configuração será na aba General;
(3) Selecionar o local onde está o nosso arquivo;
(4) Configurações referente ao nosso arquivo (Se ele é delimitado ou não, se possui um qualificador de texto, se a primeira linha do arquivo contém ou não o cabeçalho das colunas etc);
(4) Clicar em OK para confirmar.
4.1 - Configurando o Componente Source Assistant
Conforme imagem anterior, vamos fazer uso de 3 componentes! Um para a nossa origem de dados e um para o destino dos dados.
(1) Em SSIS Toolbox, vamos selecionar o componente Source Assistant;
(2) Feito isso a tela ao centro será carregada;
(3) Como nossa origem será um arquivo, vamos selecionar Flat File;
(4) Selecionar a conexão que criamos;
(5) Observe que algumas informações referente a origem do arquivo é apresentada;
(6) Clicar em OK para confirmar.

4.3 - Configurando o Componente Destination Assistant
(1) Em SSIS Toolbox, vamos selecionar o componente Destination Assistant;
(2) Feito isso a tela ao centro será carregada;
(3) Como nossa origem será um arquivo, vamos selecionar SQL Server;
(4) Selecionar a conexão que criamos;
(5) Observe que algumas informações referente ao destino do arquivo é apresentada;
(6) Clicar em OK para confirmar.

Após a inclusão do componente de Source, vamos selecionar de onde (tabela) os dados deverão ser carregados.
(1) Clicar duas vezes sobre o componente OLE DB Source;
(2) Na aba Connection Manager;
(3) Selecionar a conexão que criamos anteriormente;
(4) Nesse passo também é possível realizar a criação de uma nova conexão;
(5) Nesse ponto podemos selecionar se a nossa origem será uma tabela ou view, caso escolha, no passo seguinte você deverá selecionar em uma lista qual a origem e também pode ser selecionado um script, caso seja escolhida essa opção, no passo seguinte você deverá informar o script de consulta;
(6) Selecionar a origem, ou tabela ou script, depende do passo anterior;
(7) É possível visualizar uma prévia dos dados;
(8) E clicar em OK para finalizar.

Agora vamos configurar o nosso Destination.
(1) Após dois cliques no componente Destination, uma tela semelhante a de baixo será carregada, vamos clicar em Mappings;
(2) A origem e destino serão apresentadas;
(3) Origem dos dados;
(4) Destino dos dados;
(5) Alterei o mapeamento para carregar as colunas criadas no passo anterior
(6) Clicar em OK para finalizar.
Observem que quando clicamos na aba Mappings, as colunas já serão carregadas com o mapeamento feito. Isso ocorre justamente porque por default, o mapeamento é feito sempre por igualdade de nome. Mais ele pode ser alterado a qualquer momento.

4.4 - Configurando Variáveis
Na tela abaixo vamos realizar a criação de algumas variáveis que serão usadas no processo de carga dos arquivos.
A principio vamos definir 4 variáveis:
arquivoCompleto
diretorioOrigem
diretorioImportado
arquivo
Vamos falar agora um pouco sobre essas variáveis.
arquivoCompleto - Essa variável é definida sem nenhum valor e será preenchida durante a leitura realizada pelo componente ForEachLoop;
diretorioOrigem - Essa variável será definida com o diretório onde os arquivos estarão disponíveis;
diretorioImportado - Essa variável será definida com o diretório para onde os arquivos serão movimentados;
arquivo - Essa variável será usada com um pedaço do nome do arquivo. Não informaremos o nome completo pois existem diversos arquivos nesse diretório, mais a frente você irá entender.
Vamos seguir explicando o que fizemos! Acompanha aqui comigo...
(1) Clicar na aba Variables;
(2) Área de definição das variáveis;
(3) Nome da variável;
(4) Escopo de criação da variável;
(4) Data type da variável;
(5) Valor que será definido para variável;

4.5 - Configurando o Componente Execute SQL Task
Após configurar as variáveis, vamos voltar para o Control Flow e realizar as configurações finais. Conforme ocorreu com o post anterior que falamos sobre o File System Task, o componente de principal desse post está no Control Flow porém precisamos primeiro importar o arquivo para depois aplicar as configurações do componente.
Vamos adicionar nesse momento o componente Execute SQL Task que será responsável por realizar a limpeza na tabela antes de importar um arquivo.
Segue aqui comigo...
(1) Clicar na aba Control Flow, depois clicar em SSIS Toolbox e selecionar o componente Execute SQL Task;
(2) Nome do componente;
(3) Nesse passo vamos configurar apenas a aba General do componente Execute SQL Task;
(4) Informar o nome desse passo dentro do nosso fluxo;
(5) Selecionar a conexão, vamos usar a que criamos anteriormente;
(6) Incluir um script de TRUNCATE TABLE;
(7) Clicar em OK para finalizar.

4.4 - Configurando o Componente Foreach Loop
Agora vamos falar um pouco sobre o componente principal do nosso post.
Nesse tópico vamos estar dando ênfase a um componente que será usado para ler um diretório, e de acordo com a configuração realizada, identificar todos os arquivos que estão nele.
Feito isso ele irá informar um arquivo de cada vez para a configuração da conexão que por sua vez irá carregar um arquivo por vez e no final o componente File System Task estará responsável por mover esse arquivo e o fluxo retorna para o inicio, ficando em um loop até que todos os arquivos existentes nesse diretório tenham sido processados.
Nos próximos passos vamos falar porque escolhemos cada arquivo. Vamos dar o pontapé inicial então!
Primeiro passo da configuração do componente será informar um nome para ele dentro do nosso fluxo.
(1) Na aba General;
(2) Em Name vamos informar o nome do componente;

Avançando para a aba Collection, vamos adicionar os parâmetros que serão usados para definir o local onde estão os arquivo que serão usados.
Na aba Collection vamos configurar dois parâmetros: Diretório (Directory) e Arquivo (FileSpec).
(1) Aba Collection;
(2) Em Expressions, vamos clicar no botão que aparece para informar a primeira variável;
(3) Em Property vamos selecionar Directory e clicar no quadradinho que tem em Expression;
(4) Selecionar a variável referente ao diretório onde estão os arquivos;
(5) Após localizar a variável basta arrastar até esse local;
(6) Clicamos em Evaluate Expression para verificar o valor da variável;
(7) Após o passo (6), o valor é apresentado nesse local;
(8) Estando tudo OK, clicar para prosseguir;

Nesse momento vamos configurar o nome do arquivo.
(1) Continuando na aba Collection;
(2) Em Expressions, vamos clicar no botão que aparece para informar a segunda variável;
(3) Em Property vamos selecionar FileSpec e clicar no quadradinho que tem em Expression;
(4) Selecionar a variável referente ao arquivo;
(5) Após localizar a variável basta arrastar até esse local;
(6) Clicamos em Evaluate Expression para verificar o valor da variável;
(7) Após o passo (6), o valor é apresentado nesse local;
(8) Estando tudo OK, clicar para prosseguir;

Agora vamos avançar para a aba Variable Mappings e selecionar a nossa variável que estará recebendo o caminho + o nome do arquivo.
Isso só é possível porque na tela anterior especificamos em Retrieve file name a opção Fully qualified. Quando definimos essa configuração, estamos informação ao componente que ele precisa concatenar o diretório + o nome do arquivo e formar um único valor.

Vamos ver como que fica!
(1) Aba Variable Mappings;
(2) Em Variable, vamos clicar na setinha pra baixo e selecionar nossa variável responsável por receber o nome completo da variável;
(3) Estando tudo OK, clicar para prosseguir;

Agora é o momento em que associamos o nome completo do nosso arquivo a nossa conexão com ele.
Isso é necessário pois como vamos carregar vários arquivos, nosso componente Flat File Connection, deve estar preparado para trabalhar dessa forma e a única forma disso acontecer é fazendo dessa forma.
É bem simples, segue comigo aqui.
(1) Clicar sobre a conexão com o arquivo, apertar o botão F4 e na janela Properties procurar por Expressions e clicar no quadradinho existente;
(2) Feito isso, a configuração é bem semelhante com a que fizemos anteriormente. Em Property vamos selecionar ConnectionString e em Expression clicar no quadradinho;
(3) Selecionar a variável arquivoCompleto e arrastar até esse local;
(4) Feito isso ela será definida;
(5) Estando tudo OK, clicar para prosseguir;

Processo de configuração do For Each finalizado. Vamos avançar agora para configurar o File System Task.
4.4 - Configurando o Componente File System Task
Vamos utilizar esse componente para realizar a movimentação do arquivo que foi importado para o diretório importado.
Esse passo é de extrema necessidade pois caso isso não seja feito, toda vez que o processo for executado ele estará importando sempre os mesmos arquivos.
Agora pensa em um cenário semelhante ao que possuo aqui na empresa que trabalho onde por dia são gerados em média 200 arquivos.
Se você não separar o que já foi processado do que ainda não foi processado, você ficará com um diretório gigantesco e processando dados que já foram processados.
Esse passo agora é o mesmo que realizamos no post anterior que falamos sobre o File System Task.
Vamos usar a operação Move File, ela será responsável por movimentar os arquivos importados do diretório de origem para o diretório importado. Bem simples!
(1) Clicar na aba Control Flow, depois clicar em SSIS Toolbox e selecionar o componente File System Task e realizar um duplo clique sobre ele;
(2) Na aba General;
(3) Como estaremos trabalhando com variável, em IsDestinationPathVariable vamos alterar de False pra True;
(4) Selecionar a variável que possui a informação do diretório que o arquivo deve ser movido;
(5) Alterar a opção OverwriteDestination de False para True. Essa configuração irá permitir que sempre que um arquivo com o mesmo nome existir no diretório de destino ele será sobrescrito;
(6) Informar um nome para o componente dentro do fluxo;
(7) Vamos selecionar a opção da operação que será realizada pelo componente, no nosso caso será Move File;
(8) De mesmo modo que realizamos no item (3) vamos alterar de False para True, informando que estaremos usando variável;
(9) Informar o nome da variável que possui o caminho completo do arquivo;
(10) Clicar em OK para finalizar.

Pronto Nosso fluxo foi concluído com sucesso!

Pronto depois que configuramos todo o fluxo vamos adicionar nele a rotina para poder monitorar toda a sua execução.
5 - Criação do Banco de Log - LOG_SSIS
Esse banco será usado para armazenar toda a rotina de execução dos nossos pacotes.
Após a criação do banco vamos precisar criar uma nova conexão em nosso ETL.
Esse banco vamos chamar de LOG_SSIS.
Bora realizar a criação desse banco!
USE [master]
GO
/****** Object: Database [LOG_SSIS] Script Date: 23/12/2021 20:21:07 ******/
CREATE DATABASE [LOG_SSIS]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'LOG_SSIS', FILENAME = N'D:\SQL2012\DADOS\LOG_SSIS.mdf' , SIZE = 4096KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'LOG_SSIS_log', FILENAME = N'D:\SQL2012\LOG\LOG_SSIS_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
ALTER DATABASE [LOG_SSIS] SET COMPATIBILITY_LEVEL = 110
GOVou disponibilizar o script de criação desse banco no GitHub.

Com o banco de dados criado, podemos seguir com a configuração do nosso banco de Log.
O processo é muito semelhante ao anterior. Acompanha ai!
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New Flat File Connection;

Na próxima tela vamos informar os parâmetros necessários para criação da configuração!
(1) Na aba Connection Manager, vamos clicar com o botão direito e selecionar OLE DB Connection Manager. Na tela que será apresentada, vamos clicar em New e selecionar Native OLE DB\SQL Server Native Client 11.0;
(2) Informar o nome do servidor\instância;
(3) Selecionar o método de conexão;
(4) Selecionar o banco de dados. Clicando na setinha pra baixo é possível visualizar todos os bancos existentes em nosso servidor, nesse caso será com a base LOG_SSIS;
(5) Clicar em Test Connection para validar a conexão (Sempre comento que esse passo é desnecessário, pois ela já foi validada no passo anterior);
(6) Clicar em OK para finalizar.

Está ficando bom! Depois de criado banco e a conexão, agora vamos precisar criar três tabelas e uma procedure.
Tabela
TB_Carga - Irá armazenar informações referente ao processo de execução de um pacote de ETL como data/hora de inicio e termino da execução e status da carga;
TB_CargaDetalhe - Irá armazenar informações detalhadas da carga como quais passos já que foram executados, quantidade de registros armazenados;
TB_CargaErro - Irá armazenar informações detalhadas da carga com erro;
Procedure
STP_SIU_CarregaLog - Processo responsável por persistir as informações nas tabelas;
STP_SIU_CarregaLogErro - Processo responsável por persistir as informações quando ocorrer um erro durante o processamento;
Nesse passo vamos voltar ao nosso Client do SQL Server e criar toda a nossa estrutura de log.
(1) Conectar na instância;
(2) Selecionar o banco de dados;
(3) Tabelas criadas;
(4) Procedures criadas;

6 - Configurando a rotina de log no ETL
Quando preparamos nosso pacote de ETL no SSIS estamos falando na configuração de eventos que são disparados mediante ao disparo de alguma ação.
Em nosso exemplo vamos trabalhar com apenas 3 tipos que são eles:
OnError - Esse evento é gerado por um executável quando ocorre um erro;
OnPreExecute - Esse evento é gerado por um executável imediatamente antes da sua execução (Inicio do Processamento);
OnPostExecute - Esse evento é gerado por um executável logo depois que este termina de ser executado (Término do Processamento).
Vou deixar um link para que vocês possam ter acesso a documentação oficial da Microsoft sobre Event Handler.
Essa configuração será feita de duas formas, na primeira etapa vamos configurar a nível de Control Flow onde realizamos a configuração a nível de pacote e na segunda vamos configurar para o nosso Data Flow onde estaremos logando um fluxo.
Lembrando que o nosso fluxo foi desenvolvido de forma bem básica mesmo.
1 - Usamos um componente Execute SQL Task para limpar a tabela antes de ser carregada;
2 - Colocamos também um componente de ForEach Loop Container para poder ler o nosso diretório e selecionar todos os arquivos que precisam ser importados;
3 - Dentro do ForEach Loop Container adicionamos dois outros componente, um de Data Flow para poder fazer a importação dos dados, e um para realizar a movimentação dos arquivos importados
Conforme imagem abaixo!

Nessa nova configuração vamos usar no Control Flow também cinco componentes. Porém com a seguinte alteração ele passará a ser da seguinte forma:
1 - O componente de Execute SQL Task passará a criar uma tabela temporária e não mais limpar;
2 - O componente de ForEach Loop Container funcionará da mesma forma, lendo o diretório e selecionado os arquivos;
3 - O componente de Data Flow sofrerá uma mudança mais radical! Ele agora além de carregar o arquivo para que os dados possam ser inseridos na tabela, ele também irá identificar com a ajuda do Lookup qual registro existe e qual não existe para direcionar para seu destino correto;
4 - O componente File System Task, usado para movimentar os arquivos continuará tendo o mesmo comportamento, movimentando todos os arquivos após serem importados;
5 - E por último vamos adicionar um componente de Execute SQL Task para realizar o Update dos dados existentes.
Fincando da seguinte forma.

No Data Flow ficará assim

Vamos iniciar os trabalhos pelo Control Flow!
Conforme a tela abaixo, nosso trabalho será iniciado clicando em Event Handler.

Em nível de Control Flow vamos realizar três tipos de Event Handler:
OnError
OnPosExecute
OnPreExecute
Vamos iniciar a configuração pelo evento OnError.
Conforme explicamos acima, esse evento será disparado em caso de erro.
A configuração dele é bem simples e será realizada sempre dois momentos:
Habilitar o evento;
Adicionar o componente Execute SQL Task para disparo do processo que irá gravar em banco o evento. Nesse caso vamos usar uma procedure para evento de erro e outra procedure para os eventos OnPostExecute e o OnPreExecute.
Você vai observar que as configurações são bem parecidas o que vai mudar será que para o evento de erro iremos usar uma procedure especifica e nos parâmetros vamos definir o tipo de execução como '' (branco ou vazio) e ao acionar a procedure esse valor é alterado para E de erro, e para os demais quando criamos a configuração do evento OnPreExecute para as colunas QtdLinhasInseridas e QtdLinhasAlteradas serão definidas como 0 e o tipo de execução como I de iniciado e quando for OnPostExecute iremos informar o valor capturado pelo componente Row Count para as variáveis QtdLinhasAlteradas e QtdLinhasInseridas e o tipo de execução receberá F de finalizado.
Vamos começar os trabalhos...
(1) Na aba Event Handlers;
(2) Indica em que nível estamos realizando a configuração;
(3) Tipo de evento que será executado;
(4) Clicar para habilitar a criação.

Após selecionar o evento que precisamos incluir em nosso fluxo, vamos adicionar o componente Execute SQL Task para configurar o disparo da procedure.
(1) Na aba SSIS Toolbox, vamos selecionar o componente Execute SQL Task;
(2) Duplo clique no componente;
(3) Informar o nome para o componente;
(4) Selecionar a conexão;
(5) Em SQLStatement vamos clicar no quadrinho que tem para habilitar a tela para informar q query;
(6) Incluir a chamada da procedure que identificar um processamento com erro
EXECUTE [dbo].[STP_SIU_CarregaLogErro]
?
,?
,?
,?
,?
,'';
(7 e 8) Clicar em OK para finalizar.
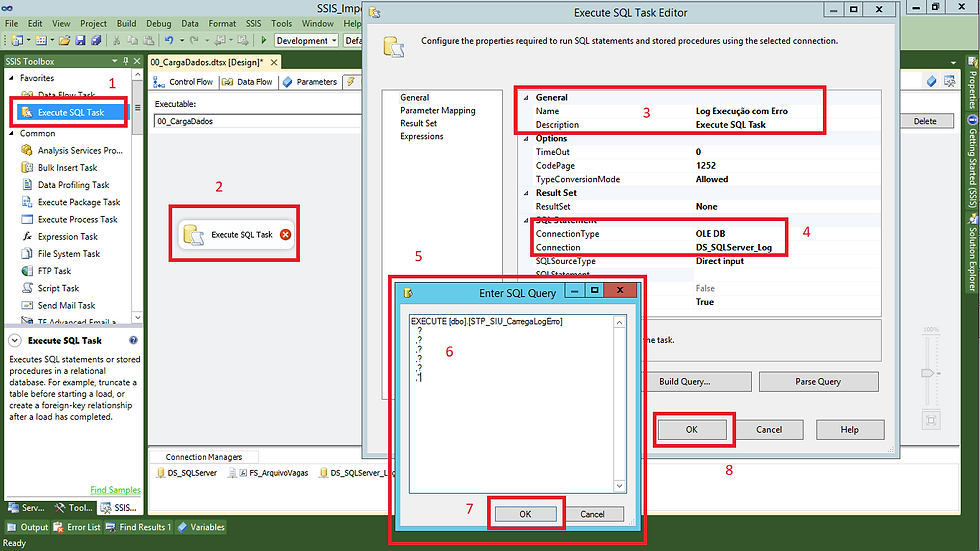
Continuando no componente Execute SQL Task, vamos fazer a configuração da aba Parameter Mapping.
Quando incluímos a procedure na aba General, definimos alguns parâmetros de entrada com uma ? (sinal de interrogação). Isso é feito para que seja possível fazer o mapeamento dentro do SSIS, mesmo processo que apresentei quando falamos do componente OLE DB Command. Agora com as entradas dos parâmetros definidas, é nesse momento em que definimos quais são os valores que serão passados para a procedure que será responsável por logar o processo quando ocorrer algum tipo de erro.
Você irá perceber que vamos repetir esses passos outras 4 vezes. Isso se faz necessário pois precisamos configurar 3 entradas (OnError, OnPreExecute e OnPostExecute) de log a nível de Control Flow e 1 (OnPostExecute) a nível de Data Flow.
Vou usar o mesmo texto porém com pequenas alterações.
(1) Na aba Parameter Mapping, selecionar as variáveis que serão preenchidas na chamada da procedure;
(2) Selecionar datatype das colunas;
(3) Sequencia dos parâmetros;
(4) Caso precise adicionar um novo parâmetro basta clicar em Add;
(5) Clicar em OK para finalizar.

Agora vamos iniciar a configuração do Event Handler OnPreExecute, exatamente identico ao anterior.
(1) Na aba Event Handlers;
(2) Indica em que nível estamos realizando a configuração;
(3) Tipo de evento que será executado;
(4) Clicar para habilitar a criação.
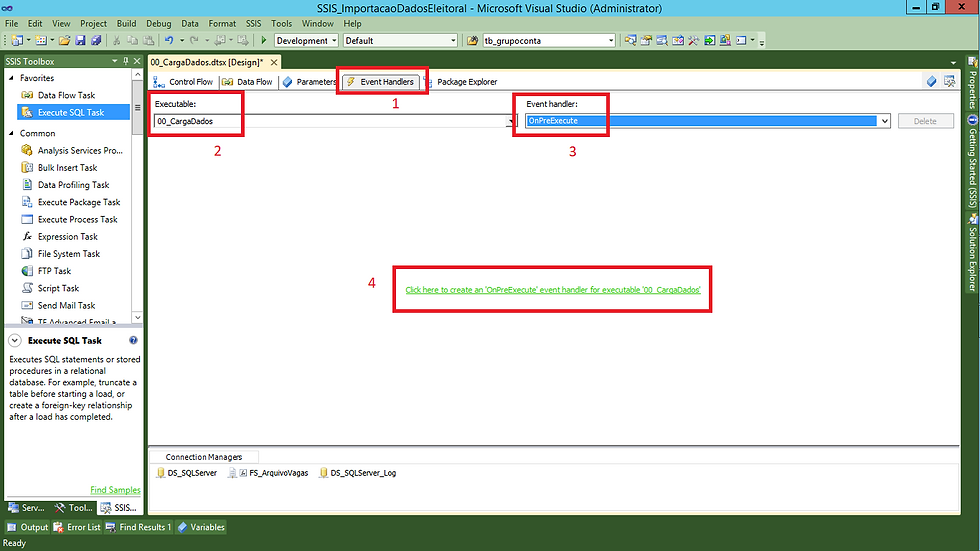
Vamos adicionar o componente Execute SQL Task para configurar o disparo da procedure.
(1) Na aba SSIS Toolbox, vamos selecionar o componente Execute SQL Task;
(2) Duplo clique no componente;
(3) Informar o nome para o componente;
(4) Selecionar a conexão;
(5) Em SQLStatement vamos clicar no quadrinho que tem para habilitar a tela para informar a query;
(6) Incluir a chamada da procedure;
A nossa procedure espera receber os seguintes parâmetros em sus chamada.
EXECUTE [dbo].[STP_SIU_CarregaLog]
@Grupo char(3) -- Variável que será criada no próximo passo
,@IdPacote varchar(50) = ''
,@NomePacote varchar(70) = ''
,@IdTarefa varchar(50) = ''
,@NomeTarefa varchar(70) = ''
,@Descricao varchar(200) = ''
,@QtdLinhasInseridas bigint = 0
,@QtdLinhasAtualizadas bigint = 0
,@TipoExecucao char(1) --I-iniciado / F-finalizado / E-erro
(7 e 8) Clicar em OK para finalizar.
Quando estamos configurando a chamada da procedure em OnPreExecute os valores para os parâmetros da procedures QtdLinhasInseridas e QtdLinhasAtualizadas devem ser informados com valor zero.

Vamos precisar criar uma variável do tipo Grupo e informar um valor para ela.
Nesse nosso exemplo vamos informar o valor ETL para ela.

Vamos voltar no componente Execute SQL Task dando duplo clique e vamos fazer a configuração da aba Parameter Mapping.
Quando incluímos a procedure na aba General, definimos alguns parâmetros de entrada com uma ? (sinal de interrogação). Isso é feito para que seja possível fazer o mapeamento dentro do SSIS, mesmo processo que apresentei quando falamos do componente OLE DB Command. Agora com as entradas dos parâmetros definidas, é nesse momento em que definimos quais são os valores que serão passados para a procedure que será responsável por logar o processo iniciar.
(1) Na aba Parameter Mapping, vamos adicionar 6 variáveis que serão passadas na chamada de procedure;
(2) Selecionar datatype das colunas;
(3) Sequencia dos parâmetros;
(4) Caso precise adicionar um novo parâmetro basta clicar em Add;
(5) Clicar em OK para finalizar.

Agora vamos iniciar a configuração do Event Handler OnPosExecute, exatamente idêntico ao anterior.
(1) Na aba Event Handlers;
(2) Indica em que nível estamos realizando a configuração;
(3) Tipo de evento que será executado;
(4) Clicar para habilitar a criação.

Vamos adicionar o componente Execute SQL Task para configurar o disparo da procedure.
(1) Na aba SSIS Toolbox, vamos selecionar o componente Execute SQL Task;
(2) Duplo clique no componente;
(3) Informar o nome para o componente;
(4) Selecionar a conexão;
(5) Em SQLStatement vamos clicar no quadrinho que tem para habilitar a tela para informar a query;
(6) Incluir a chamada da procedure
EXECUTE [dbo].[STP_SIU_CarregaLog]
?
,?
,?
,?
,?
,?
,0
,0
,'F';
(7 e 8) Clicar em OK para finalizar.

Continuando no componente Execute SQL Task, vamos fazer a configuração da aba Parameter Mapping.
Quando incluímos a procedure na aba General, definimos alguns parâmetros de entrada com uma ? (sinal de interrogação). Isso é feito para que seja possível fazer o mapeamento dentro do SSIS, mesmo processo que apresentei quando falamos do componente OLE DB Command. Agora com as entradas dos parâmetros definidas, é nesse momento em que definimos quais são os valores que serão passados para a procedure que será responsável por logar quando o processo finalizar.
(1) Na aba Parameter Mapping, vamos adicionar 6 variáveis que serão passadas na chamada de procedure;
(2) Selecionar datatype das colunas;
(3) Sequencia dos parâmetros;
(4) Caso precise adicionar um novo parâmetro basta clicar em Add;
(5) Clicar em OK para finalizar.

Concluímos a configuração a nível de Control Flow, agora vamos fazer a configuração do nosso Data Flow.
(1) Em Executable vamos clicar na caixinha com a seta pra baixo;
(2) Selecionar o Data Flow que criamos e selecionar em Event Handler selecionar OnPostExecute;
(3) Clicar em OK para finalizar.

Após a definição do evento que iremos configurar a nível de Data Flow, vamos criar duas variáveis, onde uma será QtdLinhasAtualizadas e a outra QtdLinhasInseridas ambas com data type Int32.

Vamos adicionar as duas variáveis, vamos dar um duplo clique no componente Execute SQL Task para configurar o disparo da procedure.
(1) Na aba SSIS Toolbox, vamos selecionar o componente Execute SQL Task;
(2) Duplo clique no componente;
(3) Informar o nome para o componente;
(4) Selecionar a conexão;
(5) Em SQLStatement vamos clicar no quadrinho que tem para habilitar a tela para informar a query;
(6) Incluir a chamada da procedure;
(7 e 8) Clicar em OK para finalizar.

Continuando no componente Execute SQL Task, vamos fazer a configuração da aba Parameter Mapping além das informações que passamos nos passos anteriores, vamos mapear as duas variáveis que criamos.
Quando incluímos a procedure na aba General, definimos alguns parâmetros de entrada com uma ? (sinal de interrogação). Isso é feito para que seja possível fazer o mapeamento dentro do SSIS, mesmo processo que apresentei quando falamos do componente OLE DB Command. Agora com as entradas dos parâmetros definidas, é nesse momento em que definimos quais são os valores que serão passados para a procedure que será responsável por logar quando o processo iniciar.
Diferente do que ocorrer no processo de rotina de log a nível de Control Flow, quando tratamos de Data Flow, precisamos usar essas duas variáveis pois vamos precisar saber quantos registros caíram no fluxo de inserção e atualização.

6.1 - Criando Outra Conexão
Agora após concluir a configuração do fluxo de log de Control Flow e Data Flow, vamos voltar para o nosso fluxo e dar continuidade no desenvolvimento.
Vamos precisar criar uma conexão com o nosso banco TempDB pois iremos trabalhar com tabelas temporárias.
Para você que vem acompanhando minhas postagens, esse passo já está correndo na veia. Vamos fazer mais uma vez!
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New OLE DB Connection;

Após definir o tipo de conexão, vamos informar qual o conector, servidor\instância, qual a conexão que será usada, usuário (de acordo com o método de autenticação selecionado) e banco de de dados.
Vamos lá, já estamos careca de saber como que funciona!
(1) Na aba Connection Manager, vamos clicar com o botão direito e selecionar OLE DB Connection Manager. Na tela que será apresentada, vamos clicar em New e em Provider selecionar Native OLE DB\SQL Server Native Client 11.0;
(2) Informar o nome do servidor\instância e o método de conexão;
(3) Em nossa lista de bancos vamos selecionar o banco TempDB;
(4) Clicar em Test Connection para validar a conexão (Sempre comento que esse passo é desnecessário, pois ela já foi validada no passo anterior);
(5) Clicar em OK para finalizar.

Vamos dar um duplo clique em nosso fluxo para visualizar como que ele era.

Vou desmonta-lo para colocar no formato que precisamos.

Vou adicionar um componente Lookup em nosso fluxo.
(1) Em SSIS Toolbox selecionar o componente Lookup e arrastar parar o fluxo;
(2) Ligar o componente de Source com o componente Lookup e depois realizar um duplo clique sobre o componente Lookup;
(3) Na aba General, clicar na setinha para baixo para configurar o fluxo de output para quando não existir os dados;
(4) Selecionar a opção Redirect rows to no match output.;

Agora na aba Connection vamos fazer a seleção da origem dos dados.
(1) No componente de Lookup;
(2) Na aba Connection;
(3) Selecionar a conexão;
(4) Caso não encontre a conexão, existe a possibilidade de criar;
(5) Selecionar a tabela;
(6) Caso não encontre a tabela, existe a possibilidade de criar;
(7) Clicar para visualizar uma amostra de dados;
(8) Clicar em OK para finalizar.

Agora na aba Columns vamos estabelecer a relação entre o Source e a origem definida no componente Lookup.

Com isso preparamos nosso fluxo para validar a existência ou não dos dados no destino antes de inserir.
Para transformar nosso processo mais robusto, precisamos criar uma conexão com o banco TempDB. Essa conexão faz-se necessário pois durante nosso fluxo, vamos criar uma tabela temporária para receber os dados existentes no destino.
Vamos ver como que fica o script de criação da nossa tabela!
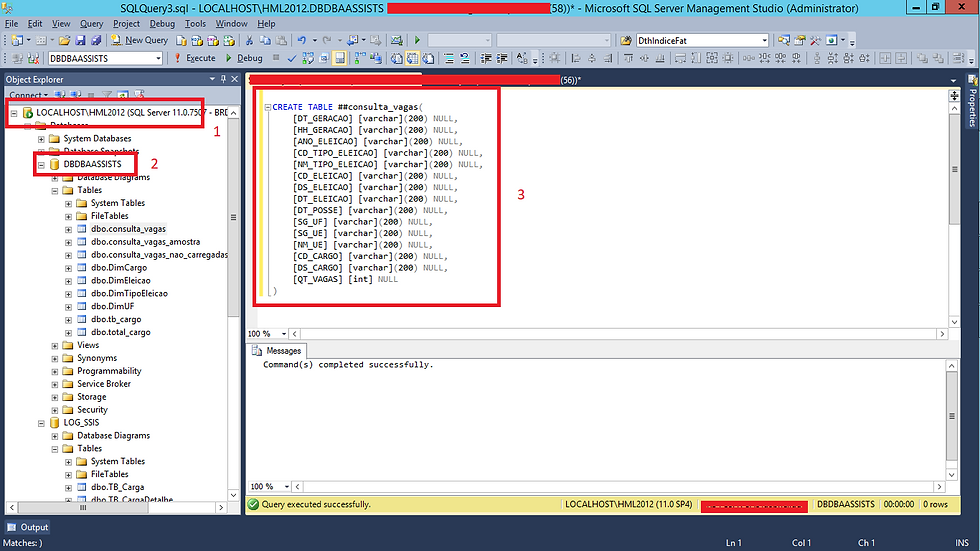
Feito isso, vamos voltar em nosso Control Flow e alterar a configuração que realizamos no passo 4.5 onde adicionamos um componente de Execute SQL Task para realizar um Truncate Table. Com essa alteração, vamos fazer com que esse passo crie a tabela temporária que será usada em nosso passo de Lookup. Vamos seguir seguir os passos para a configuração.

Após alterar o primeiro passo do nosso ETL, vamos concentrar agora as alterações em nosso Data Flow. Vamos configurar o fluxo de existência de dados.
Lembrando que para o mapeamento, você precisa ter criado a sua tabela temporária no banco! Se não fizer isso irá apresentar erro ao tentar mapear a tabela e os seus campos!
Vamos então para configuração!
(1) Vincular a Origem com o Lookup;
(2) Vincular o Lookup ao componente de Row Count, justamente para sabermos quantos registros serão atualizados;
(3) Duplo clique no componente Row Cout para que possamos selecionar a variável que irá receber os valores;
(4) Selecionar a variável QtdLinhasAtualizadas;
(5) Clicar em OK para confirmar.

E de mesmo modo vamos fazer para os registros novos.

Ao concluir nossa configuração nosso fluxo ficou assim.

Após executar o fluxo, observe que todos os registros caíram no fluxo de existência.
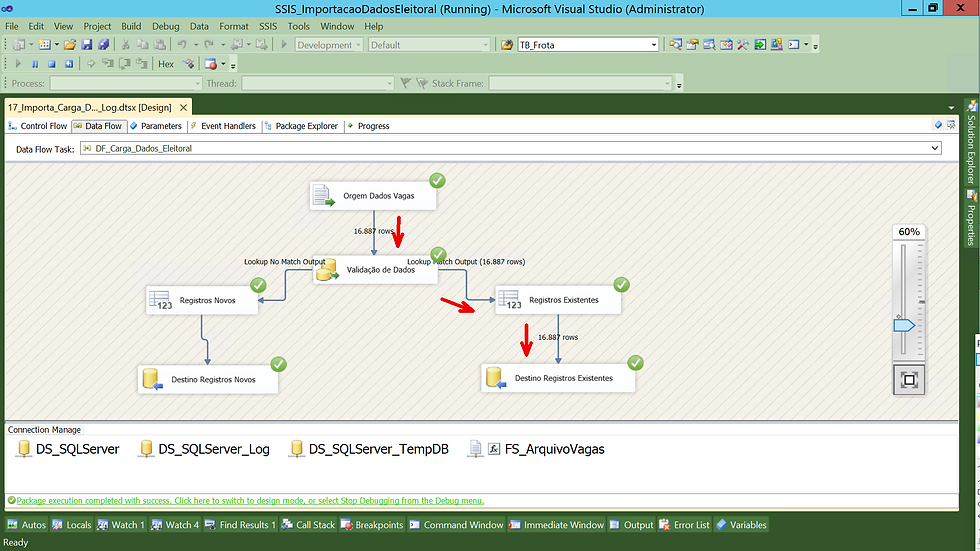
Agora vou excluir da base os dados do RJ para simular o fluxo para os dois destinos.

Com isso conseguimos visualizar que agora o fluxo flui para ambos os destinos.

Após a execução conseguimos verificar o log que foi gerado pela rotina que criamos.

Os arquivos usados até aqui estão disponíveis em:
Pacote SSIS - Criando Rotina de Log Execução
12_SCRIPT_CRIACAO_DATABASE_LOG_SSIS.sql
13_SCRIPT_CREATE_TABLE_LOG.sql
14_SCRIPT_CREATE_PROCEDURE_LOG.sql
17_Importa_Carga_Dados_Rotina_Log.dtsx
7 - Conclusão
E meu amigo, um mega post concluído!
Eu trabalho com SSIS a muitos anos e essa rotina auxilia muito durante meu processo de validação diária.
Com ele além de acompanhar as cargas, é possível também identificar se algum processamento está com tempo elevado, é possível a criação de um painel em PBI ara fazer o acompanhamento e até criar disparos diários referente as execuções.
Espero que tenham gostado e qualquer dúvida podem chamar!
Um excelente dia e uma semana abençoada.
Fiquem com Deus!
Comments