
E ai fera, pronto para o novo desafio?
Nesse super post vamos abordar a configuração e usabilidade do super componente Lookup!
Esse cara eu tenho certeza que vai andar por longos caminhos com você. Sempre que você definir que seu fluxo será sempre 100% orientado a objetos, isso significa que sempre que precisar relacionar dois datasets irá necessitar fazer uso ou do componente Merge Join ou Lookup.
Hoje é o dia do Lookup, então segue ai comigo e no final me fale se gostou ou nao!
Antes de avançar para o código, vamos fazer uma breve introdução de como iremos trabalhar nesse post.
1 - Criação de um projeto SSIS - Sempre que trabalhamos com SSIS, existe a necessidade de realizar a criação de um projeto no Visual Studio, caso tenha criado nos posts anteriores, pode utilizar sem problemas, porém caso não tenha trate de criar pois é um item obrigatório! Dentro desse projeto vamos armazenar todos os pacotes de ETL;
2 - Criação de um pacote de ETL - Quando falamos em pacotes de ETL, estamos nos referindo ao conjunto de fluxos que será usado para trafegar com a nossa informação da sua origem até seu destino. Recomento que caso esteja acompanhando nossa série, crie um pacote para cada item, fica mais fácil o entendimento;
3 - Criando/Configurando as conexões - Vamos utilizar nesse nosso post duas conexões do tipo OLE DB pois iremos consumir e gravar dados do Microsoft SQL Server, ou seja, Source (1) e Destinantion (2) irão apontar para o mesmo local, a única diferença será a tabela que será consumida e iremos gravar em dois destinos diferentes (um será uma tabela fisica e o outro uma tabela temporária). Esse é o passo onde definimos as conexão;
4 - Criando nosso Fluxo de Dados
4.1 - Componentes que serão usados - Nesse primeiro exemplo, vamos trabalhar com quatro componentes: Source Assistant (1), responsável pela conexão com a origem. Vamos consumir uma tabela do Microsoft SQL Server, iremos usar também o componente Lookup (1) esse componente será usado para validar se os dados que são carregados na origem existe no destino e por último o componente Destination Assistant (2) que será usado para definir o destino dos dados.
4.2 - Criando nosso destino dos dados (Tabela) - Vamos criar uma tabela para receber os dados;
5 - Visualizando os dados carregados - E por último, vamos visualizar como que ficaram os dados carregados em nossa tabela.
Bora começar então!
1 - Criando um Projeto no SQL Server Integration Services
Vou considerar que você não tem nenhum projeto criado no Visual Studio do SQL Server Integration Service. Um ponto bem importante desse estudo é que não irei falar como que você realiza a configuração do seu ambiente, entenderei que você já tenha feito isso em outro momento.
Para criar um projeto é bem simples. Vamos abrir o Visual Studio e seguir os próximos passos.
(1) Selecionar File;
(2) New;
(3) Project;
(4) Caso tenha um projeto criado basta clicar em Open Project.
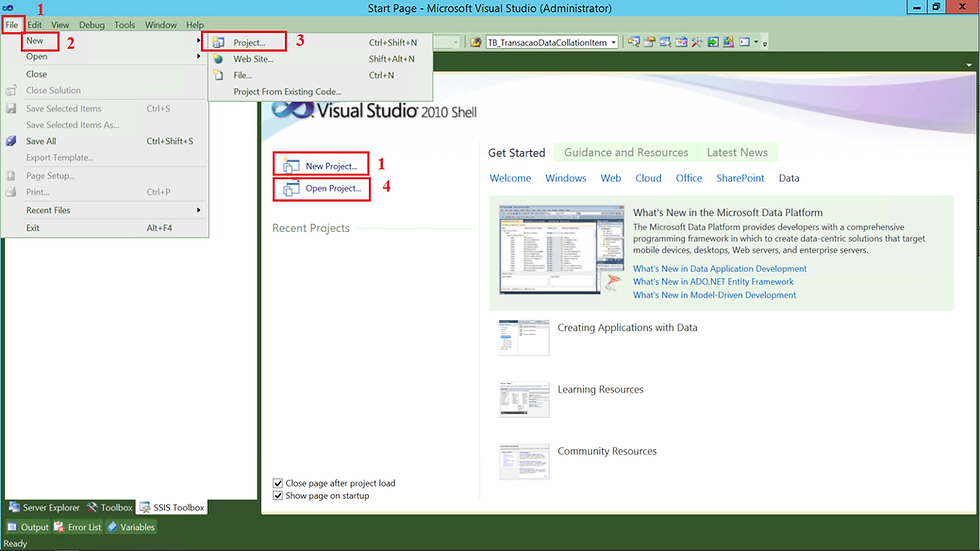
Após clicar em New Project, a tela abaixo será apresentada.
(1) Escolher Integration Services;
(2) Integration Services Project;
(3) Informar um nome para o Projeto;
(4) Definir o local (diretório) que o projeto será gerado;
(5) Informar uma nomenclatura para a sua solução;
(6) Caso queira que um diretório para o projeto seja criado basta marcar essa opção;
(7) Clicar em OK para realizar a criação;
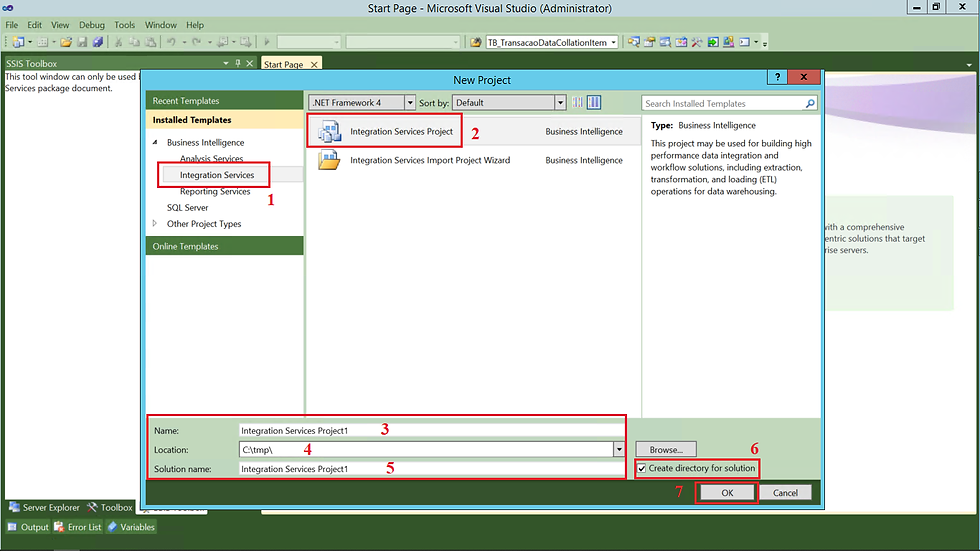
2 - Criando nosso Pacote de ETL
Primeiro ação será a criação de um pacote do SSIS. Essa criação é bem simples, acompanha comigo.
(1) Clicar com o botão direito do mouse sobre SSIS Package;
(2) Clicar em New SSIS Package;
Além dessa possibilidade, outras ações podem ser realizadas.
Importar um Arquivo dtsx - basta clicar em Add Existng Package;
Realizar o Upgrade dos seus pacotes - basta clicar sobre Convert Deployment Model ou Upgrade All Package;
Realizar um Import and Export - basta clicar sobre SSIS Import and Export Wizard;
Ordenar seus pacotes - basta clicar em Sort by name.
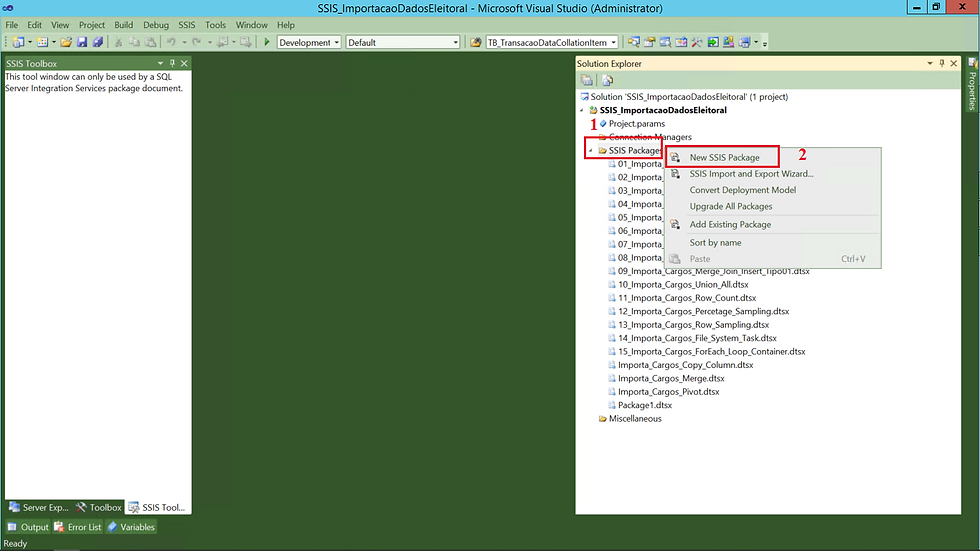
Após a criação do nosso arquivo dtsx, vamos para o desenho do nosso fluxo.
(1) Nome do arquivo dtsx;
Para alterar basta clicar sobre ele e apertar o botão F4 e em file name informar o nome do seu pacote.

Ou clicar sobre o pacote e apertar F2
(2) Aba Control Flow;
(3) Inserir um componente de Data Flow Task;
(4) Realizar duplo clique ou clicar em Data Flow.

Ao clicar em Data Flow, vamos começar a brincadeira! Dessa vez vamos fazer iguais aos filmes de Hollywood começando do final. Apresento para você como que será o resultado final desse nosso trabalho (1).

Vamos trabalhar então para produzir mais esse conteúdo.
3 - Criando as Conexões
Primeiro passo será realizar a configuração das nossas conexões.
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New OLE DB Connection;

Na próxima tela vamos realizar a parametrização da conexão. É bem simples, acompanha comigo!
(1) Na aba Connection Manager, vamos clicar com o botão direito e selecionar OLE DB Connection Manager. Na tela que será apresentada, vamos clicar em New;
(2) Selecionar Native OLE DB\SQL Server Native Client 11.0;
(3) Informar o nome do servidor\instância;
(4) Selecionar o método de conexão;
(5) Selecionar o banco de dados. Clicando na setinha pra baixo é possível visualizar todos os bancos existentes em nosso servidor;
(6) Clicar em Test Connection para validar a conexão (Sempre comento que esse passo é desnecessário, pois ela já foi validada no passo anterior);
(7) Clicar em OK para finalizar.

4 - Criando o Fluxo de Dados
Na aba Control Flow, vamos selecionar seguir os seguintes passos.
(0) Podemos observar que a conexão criada está configurada e disponível;
(1) Em SSIS Toolbox o componente Data Flow Task;
(2) Sobre o componente Data Flow Task, vamos clicar com o botão direito;
(3) Clicar em Rename.

Na próxima tela conseguimos visualizar o esqueleto (1) do nosso motor.

4.1 - Configurando o Componente Source Assistant
Conforme imagem anterior, vamos fazer uso de 3 componentes! Um para a nossa origem de dados, uma para o destino dos dados e um que permite que façamos um relacionamento entre os nossos datasetts, ou seja, ele é o objetivo desse post.
Acompanha ai como que é simples!
(1) Em SSIS Toolbox, vamos selecionar o componente Source Assistant;
(2) Feito isso a tela ao centro será carregada;
(3) Como nossa origem será uma tabela do nosso banco de dados, vamos selecionar SQL Server;
(4) Selecionar a conexão que criamos;
(5) Observe que algumas informações referente a origem dos dados é apresentada;
(6) Clicar em OK para confirmar.

Após a inclusão do componente de Source, vamos selecionar de onde (tabela) os dados deverão ser carregados.
(1) Vamos clicar duas vezes sobre o componente OLE DB Source, vamos trabalhar na na aba Connection Manager;
(2) Selecionar a conexão que criamos anteriormente;
(3) Nesse passo também é possível realizar a criação de uma nova conexão;
(4) Nesse ponto podemos selecionar se a nossa origem será uma tabela ou view, caso escolha, no passo seguinte você deverá selecionar em uma lista qual a origem e também pode ser selecionado um script, caso seja escolhida essa opção, no passo seguinte você deverá informar o script de consulta;
(5) Selecionar a origem, ou tabela ou script, depende do passo anterior;
(6) É possível visualizar uma prévia dos dados;
(7) E clicar em OK para finalizar.


Após definir os parâmetros da nossa conexão, observei que escolhemos a opção de acesso ao dado via Table or View. Quando realizamos essa configuração, estamos selecionando a tabela como um todo, ou seja, todas as colunas e todos os dados. Caso queira definir quais colunas da nossa tabela queremos carregar, basta clicar na aba Columns e selecionar quais colunas da tabela você irá utilizar, caso não faça isso, todas as colunas serão carregadas!
Muito bem aspira, após essa dica valiosa, vamos realizar a inclusão do componente de Lookup.
4.2 - Configurando o Componente Lookup
Ele também possui o comportamento semelhante ao Join entre duas tabelas e é muito usado em pacotes ETL.
O processo que vamos fazer é o seguinte:
Inserir em nosso destino, dbo.consulta_vagas_amostra todos os registros que existem em nossa origem, dbo.consulta_vagas que não existem no destino.
E como fazer isso? Bem simples! Caminha aqui comigo...
1 - Em nosso Source vamos selecionar a tabela dbo.consulta_vagas (Configuração realizada no passo anterior);
2 - Incluir o componente Lookup tendo como origem da informação a tabela dbo.consulta_vagas_amostra e relacionar as duas tabelas através das colunas CD_CARGO, CD_TIPO_ELEICAO, SG_UF e SG_UE e definir na saída do componente (item (4) abaixo) que somente os registros que não existirem devem ser carregados;
Para ficar melhor o entendimento, o que faremos a seguir é semelhante ao comando TSQL abaixo.

-- Script carga dbo.consulta_vagas_amostra
INSERT INTO dbo.consulta_vagas_amostra
(CD_CARGO,CD_TIPO_ELEICAO,SG_UF,SG_UE,DT_GERACAO,HH_GERACAO,ANO_ELEICAO,NM_TIPO_ELEICAO,CD_ELEICAO,DS_ELEICAO,DT_ELEICAO,DT_POSSE,NM_UE,DS_CARGO,QT_VAGAS)
SELECT
ConsVag.CD_CARGO,ConsVag.CD_TIPO_ELEICAO,ConsVag.SG_UF,ConsVag.SG_UE,ConsVag.DT_GERACAO,ConsVag.HH_GERACAO,ConsVag.ANO_ELEICAO,ConsVag.NM_TIPO_ELEICAO
,ConsVag.CD_ELEICAO,ConsVag.DS_ELEICAO,ConsVag.DT_ELEICAO,ConsVag.DT_POSSE,ConsVag.NM_UE,ConsVag.DS_CARGO,ConsVag.QT_VAGAS
FROM dbo.consulta_vagas ConsVag
LEFT JOIN dbo.consulta_vagas_amostra ConsVagAmo
on ConsVag.CD_CARGO = ConsVagAmo.CD_CARGO
AND ConsVag.CD_TIPO_ELEICAO = ConsVagAmo.CD_TIPO_ELEICAO
AND ConsVag.SG_UF = ConsVagAmo.SG_UF
AND ConsVag.SG_UE = ConsVagAmo.SG_UE
WHERE ConsVagAmo.CD_CARGO IS NULL
AND ConsVagAmo.CD_TIPO_ELEICAO IS NULL
AND ConsVagAmo.SG_UF IS NULL
AND ConsVagAmo.SG_UE IS NULLObserve a imagem abaixo onde é possível visualizar a tabela do Source preenchida e a do destination completamente vazia.

Após executar a query da imagem anterior, vamos ver como que ficaram.

Observe agora que quando executamos o script pela segundo vez, nenhuma linha é inserida.

Vamos seguir bem devagar e visualizar como que faremos isso via componente Lookup.
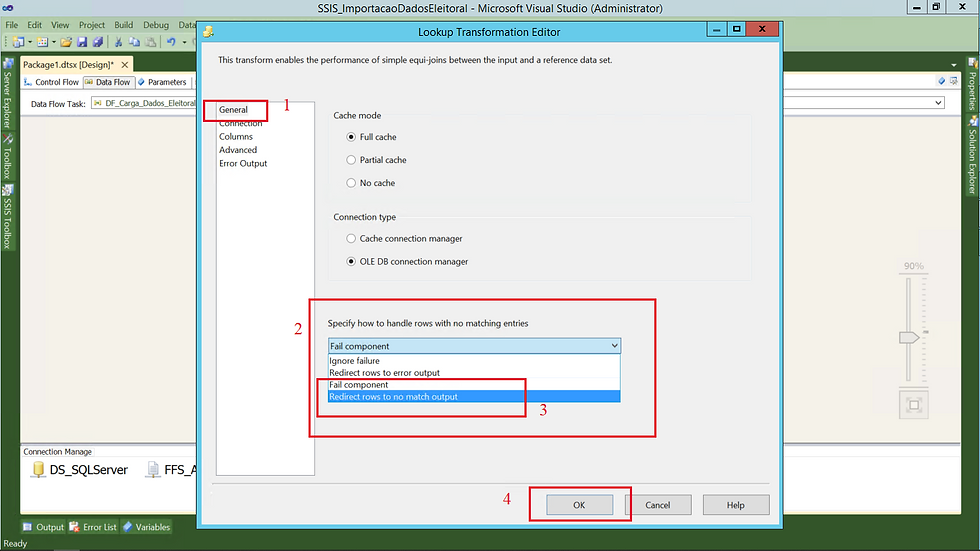
(1) Em SSIS Toolbox, vamos selecionar o componente Lookup e incluir em nosso fluxo. Feito isso, duplo clique no componente para iniciar a configuração;
(2) Para cache (Cache mode), vamos deixar Full cache;
(3) Para conexão (Connection type), vamos deixar selecionado OLE DB connection manager;
(4) Informar o que será feito caso um registro não seja encontrado (Redirect rows to no match ourput);
(5) Clicar em OK para confirmar.
No componente Lookup, podemos especificar o tipo de conexão (Connection Type) e o tipo de cache (Cache mode) que iremos usar durante o nosso processo. Esses detalhes estão fora do escopo deste artigo vamos seguir com os valores padrão deles.

Seguindo com a configuração.
Vamos definir no próximo passo com o que pretendemos comparar.
(1) Na aba connection, definimos a configuração com o objeto que será utilizado;
(2) Selecionar a conexão criada;
(3) Caso não exista a configuração, podemos estar realizando a sua criação;
(4) Selecionar a tabela onde estão os dados;
(5) De mesmo modo que o item (3) podemos estar realizando a criação caso não exista;
(6) É possível visualizar uma prévia dos dados;
(7) Caso esteja tudo pronto, clicar em OK para finalizar a configuração.

Quase acabando...
(1) E por último, na aba Columns, vamos estabelecer a relação entre os objetos;
(2) Tabelas que estaremos trabalhando;
(3) Clique com o botão direito do mouse na área e em seguida clicar em Edit Mappings;
Vamos avançar pra tela seguinte.

Ao clicar em Edit Mappings, a tela abaixo será apresentada.
(2) Selecionar a coluna que será usada para estabelecer a relação entre os objetos;
(3) Caso esteja tudo concluído, clicar em OK para confirmar.

Vamos volta na aba General para alterar um configuração.
(1) Na aba General;
(2) Em Specify how to handle rows with no matchings, clicar na setinha pra baixo;
(3) Selecionar Redirect rows to no matchings output;
(4) Clicar OK para finalizar.
Antes de continuar deixa eu explicar porque eu fiz isso.
Conforme comentado anteriormente, nessa primeira parte do nosso exemplo, vamos trabalhar inserindo em nosso destino apenas aqueles dados que não existem. Poderia adicionar o passo para atualizar os existentes, mais não vou fazer. Mais a frente vamos trabalhar com o esse comportamento.
Concluída a configuração do Source e do Lookup, vamos fazer a inclusão do nosso Destination.
4.3 - Configurando o Componente Destination Assistant
(1) Em SSIS Toolbox, vamos selecionar o componente Destination Assistant;
(2) Feito isso a tela ao centro será carregada;
(3) Como nosso destino será uma tabela no banco de dados, vamos selecionar SQL Server;
(4) Selecionar a conexão que criamos;
(5) Observe que algumas informações referente ao destino do arquivo é apresentada;
(6) Clicar em OK para confirmar.

Da mesma forma que no Source selecionamos a origem da informação, nesse passo vamos selecionar o nosso Destino.
(1) Duplo clique no componente OLE DB Destination e na aba Connection Manager;
(2) Selecionar a conexão com o banco de dados;
(3) Nesse passo é possível realizar a criação de uma nova conexão;
(4) Selecionar o modo de carga de dados;
(5) Selecionar em qual tabela os dados serão gravados;
(6) É possível criar uma tabela caso não exista;
(7) Podemos visualizar se existe algum registros em nosso destino;
(8) Clicar em OK para finalizar a configuração.

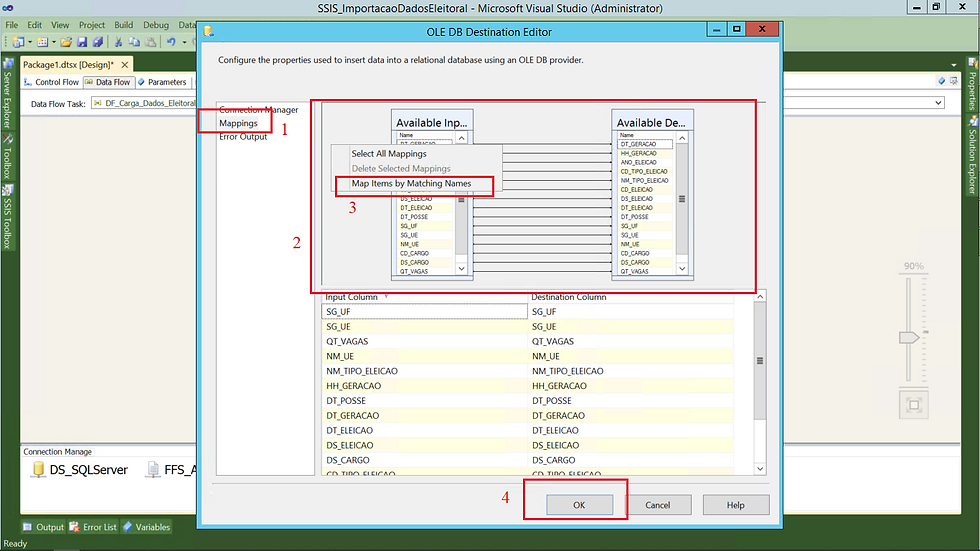
O próximo passo é realizar o mapeamento da origem com o destino.
(1) Componente OLS DB Destination na aba Mappings;
(2) Origem e destino;
(3) Selecionar a opção Map items by Matching Names, para realizar o mapeamento automático por nome;
(4) Ao concluir o mapeamento basta clicar em OK.
Não estarei abordando a aba Error Output.
Pronto! Fluxo criado com sucesso!

Para finalizar nossa configuração, vamos incluir um componente que será usado por limpar sempre o nosso destino antes da carga.
4.4 - Configurando o Componente Execute SQL Task
(1) Clicar na aba Control Flow, depois clicar em SSIS Toolbox e selecionar o componente Execute SQL Task;
(2) Nesse passo vamos configurar apenas a aba General do componente Execute SQL Task para informar um nome para o componente;
(3) Selecionar a conexão, vamos usar a que criamos anteriormente;
(4) Incluir um script de TRUNCATE TABLE;
(5) Clicar em OK para finalizar.

Pronto, configuração realizada, vamos agora executar e visualizar os dados.
(1) Fluxo dos dados;
(2) Vamos conectar em nosso servidor;
(3) Selecionar nosso banco de dados;
(4) Tabela em que os dados foram carregados;
(5) Comando de consulta dos dados.

Primeira parte concluída, agora vamos maturar nosso processo, torna-lo um pouco mais robusto!
5 - Alterando o Comportamento do Componente Lookup
Observem abaixo como que será a sua nova cara (1)!
Nesse momento vamos remover o passo de limpeza da tabela e adicionar dois novos passos.
O primeiro vamos chama-lo de "SQL Task - Cria TB Temporária" e o outro que será chamado de "SQL Task - Atualiza TB".
Tenho 110% de certeza que ai do outro lado você deve estar se perguntando por que esses os passos foram adicionados. Estou certo ou errado?
Calma cara, tu não deixa eu explicar. Vamos falar do primeiro.
No componente "SQL Task - Cria TB Temporária" vou criar uma tabela temporária como a mesma estrutura da tabela dbo.consulta_vagas_amostra para receber os dados que existem na tabela dbo.consulta_vagas_amostra.
IF OBJECT_ID ('tempdb..##tmp_consulta_vagas_amostra') is not null
DROP TABLE ##tmp_consulta_vagas_amostra;
CREATE TABLE ##tmp_consulta_vagas_amostra(
[DT_GERACAO] [varchar](200) NULL,
[HH_GERACAO] [varchar](200) NULL,
[ANO_ELEICAO] [varchar](200) NULL,
[CD_TIPO_ELEICAO] [varchar](200) NULL,
[NM_TIPO_ELEICAO] [varchar](200) NULL,
[CD_ELEICAO] [varchar](200) NULL,
[DS_ELEICAO] [varchar](200) NULL,
[DT_ELEICAO] [varchar](200) NULL,
[DT_POSSE] [varchar](200) NULL,
[SG_UF] [varchar](200) NULL,
[SG_UE] [varchar](200) NULL,
[NM_UE] [varchar](200) NULL,
[CD_CARGO] [varchar](200) NULL,
[DS_CARGO] [varchar](200) NULL,
[QT_VAGAS] [int] NULL
)E no componente "SQL Task - Atualiza TB" vou adicionar o script de update para atualizar a tabela dbo.consulta_vagas_amostra.
UPDATE A
SET
A.[DT_GERACAO] = b.[DT_GERACAO]
,a.[HH_GERACAO] = b.[HH_GERACAO]
,a.[ANO_ELEICAO] = b.[ANO_ELEICAO]
,a.[NM_TIPO_ELEICAO] = b.[NM_TIPO_ELEICAO]
,a.[CD_ELEICAO] = b.[CD_ELEICAO]
,a.[DS_ELEICAO] = b.[DS_ELEICAO]
,a.[DT_ELEICAO] = b.[DT_ELEICAO]
,a.[DT_POSSE] = b.[DT_POSSE]
,a.[NM_UE] = b.[NM_UE]
,a.[DS_CARGO] = b.[DS_CARGO]
,a.[QT_VAGAS] = b.[QT_VAGAS]
FROM [DBDBAASSISTS].[dbo].[consulta_vagas] a
inner join ##tmp_consulta_vagas_amostra b
on a.[CD_CARGO] = b.[CD_CARGO]
and a.[CD_TIPO_ELEICAO] = b.[CD_TIPO_ELEICAO]
and a.[SG_UF] = b.[SG_UF]
and a.[SG_UE] = b.[SG_UE]Ficou claro?

5.1 - Criando Outra Conexão
Agora após a apresentação de como irá ficar nosso modelo, vamos por as mãos a obra.
Vamos precisar criar uma conexão com o nosso banco TempDB pois iremos trabalhar com tabelas temporárias.
Para você que vem acompanhando minhas postagens, esse passo já está correndo na veia. Vamos fazer mais uma vez!
(1) Aba Connection Manage;
(2) Clicar com o botão direito do mouse e escolher New OLE DB Connection;

(1) Na aba Connection Manager, vamos clicar com o botão direito e selecionar OLE DB Connection Manager. Na tela que será apresentada, vamos clicar em New e em Provider selecionar Native OLE DB\SQL Server Native Client 11.0;
(2) Informar o nome do servidor\instância;
(3) Selecionar o método de conexão;
(4) Em nossa lista de bancos vamos selecionar o banco TempDB;
(5) Clicar em Test Connection para validar a conexão (Sempre comento que esse passo é desnecessário, pois ela já foi validada no passo anterior);
(6) Clicar em OK para finalizar.

Quando trabalhamos com tabelas temporárias, algumas configurações a nível de pacote precisam ser feitas.
Vamos na primeira, alterar a opção Delay Validation para True.
Mais pra que que isso serve?
Quando alteramos Delay Validation para True, estamos falando para o nosso pacote que não faça a validação dos componente quando abrimos ele.
Essa configuração é a nível de pacote e componentes! Vamos ver como procedemos com essa configuração.
(1) Fluxo novo;
(2) Clicar sobre a conexão que criamos no passo anterior e apertar o botão F4;
(3) Alterar a opção Delay Validation de False para True.

Muito bem, após criar a conexão com o banco TempDB e a realização da configuração de Delay Validation para a conexão, vamos adicionar um componente de Execute SQL Task. Esse componente será responsável pela criação da tabela temporária tmp_consulta_vagas_amostra, lembrando que essa tabela tem a mesma estrutura que a tabela dbo.consulta_vagas_amostra.
Bora então realizar a inclusão/configuração do componente.
(1) Clicar na aba Control Flow, depois clicar em SSIS Toolbox e selecionar o componente Execute SQL Task;
(2) Na aba General do componente Execute SQL Task informar um nome para o componente;
(3) Selecionar a conexão que criamos no passo anterior;
(4) Incluir um script para criação de uma tabela temporária;
(5) Clicar em OK para finalizar.
-- SCRIPT DE CRIAÇÃO DA TABELA TEMPORÁRIA
IF OBJECT_ID ('tempdb..##tmp_consulta_vagas_amostra') is not null
DROP TABLE ##tmp_consulta_vagas_amostra;
CREATE TABLE ##tmp_consulta_vagas_amostra(
[DT_GERACAO] [varchar](200) NULL,
[HH_GERACAO] [varchar](200) NULL,
[ANO_ELEICAO] [varchar](200) NULL,
[CD_TIPO_ELEICAO] [varchar](200) NULL,
[NM_TIPO_ELEICAO] [varchar](200) NULL,
[CD_ELEICAO] [varchar](200) NULL,
[DS_ELEICAO] [varchar](200) NULL,
[DT_ELEICAO] [varchar](200) NULL,
[DT_POSSE] [varchar](200) NULL,
[SG_UF] [varchar](200) NULL,
[SG_UE] [varchar](200) NULL,
[NM_UE] [varchar](200) NULL,
[CD_CARGO] [varchar](200) NULL,
[DS_CARGO] [varchar](200) NULL,
[QT_VAGAS] [int] NULL
)
E agora vamos realizar a configuração do outro componenete que será responsável pela atualização da tabela dbo.consulta_vagas_amostra baseada na tabela temporaria tmp_consulta_vagas_amostra.
Vamos ver como que fica! É muito semelhante ao passo anterior!
(1) Clicar na aba Control Flow, depois clicar em SSIS Toolbox e selecionar o componente Execute SQL Task;
(2) Na aba General do componente Execute SQL Task informar um nome para o componente;
(3) Selecionar a conexão que criamos no passo anterior;
(4) Incluir um script para atualização dos dados na tabela final;
(5) Clicar em OK para finalizar.
-- SCRIPT DE ATUALIZAÇÃO DOS DADOS
UPDATE A
SET A.[DT_GERACAO] = b.[DT_GERACAO]
,a.[HH_GERACAO] = b.[HH_GERACAO]
,a.[ANO_ELEICAO] = b.[ANO_ELEICAO]
,a.[NM_TIPO_ELEICAO] = b.[NM_TIPO_ELEICAO]
,a.[CD_ELEICAO] = b.[CD_ELEICAO]
,a.[DS_ELEICAO] = b.[DS_ELEICAO]
,a.[DT_ELEICAO] = b.[DT_ELEICAO]
,a.[DT_POSSE] = b.[DT_POSSE]
,a.[NM_UE] = b.[NM_UE]
,a.[DS_CARGO] = b.[DS_CARGO]
,a.[QT_VAGAS] = b.[QT_VAGAS]
FROM [DBDBAASSISTS].[dbo].[consulta_vagas] a
inner join ##tmp_consulta_vagas_amostra b
on a.[CD_CARGO] = b.[CD_CARGO]
and a.[CD_TIPO_ELEICAO] = b.[CD_TIPO_ELEICAO]
and a.[SG_UF] = b.[SG_UF]
and a.[SG_UE] = b.[SG_UE]
Agora é o momento de realizar a configuração de Delay Validation para os dois componente que adicionamos. É exatamente igual ao que realizamos anteriormente na conexão com o tempdb.
No primeiro...
(1) Clicar sobre o componente e apertar F4;
(2) Alterar a opção Delay Validation de False para True.

E para o segundo a mesma coisa...
(1) Clicar sobre o componente e apertar F4;
(2) Alterar a opção Delay Validation de False para True.

E vamos realizar também essa configuração para o nosso componente de Data Flow.
(1) Clicar sobre o componente e apertar F4;
(2) Alterar a opção Delay Validation de False para True.

Após a configuração dos dois componentes de Execute SQL Task, é hora de incluir o segundo componente que será usado para armazenar em nossa tabela temporária os dados existentes na tabela de destino.
Vamos clicar em Data Flow para incluir um novo destino.
(1) Em SSIS Toolbox, vamos selecionar o componente Destination Assistant;
(2) Feito isso a tela ao centro será carregada;
(3) Como nosso destino será uma tabela do banco de dados, vamos selecionar SQL Server;
(4) Selecionar a conexão que criamos com o banco tempdb;
(5) Observe que algumas informações referente ao destino do arquivo é apresentada;
(6) Clicar em OK para confirmar.

Novo fluxo montado! Observe que agora possuímos dois destinos.
Ao iniciarmos o processamento, os dados podem seguir dois destinos, ou serão inseridos diretamente na tabela destino ou serão inseridos na tabela temporária.
Quando ocorrer a inserção imediata dos dados, podemos dizer que o evento No Match ocorreu, ou seja, quando não existe os dados no destino;
E quando ocorrer a inserção na tabela temporária, podemos dizer que o evento Match ocorreu, ou seja, significa que os dados existem no destino, devem ser redirecionados para serem inseridos na tabela temporária e no final do processamento os dados do destino serão atualizados.
Vamos seguir com a configuração.
Observe que o novo componente de destino está com um X, assinalando um erro. Vamos corrigir!

Vamos voltar no Microsoft SQL Server e realizar a criação da nosso tabela temporária.
(1) Conectar no nosso servidor;
(2) Selecionar o banco de dados e depois clicar em New Query;
(3) Executar o script para criar a tabela temporária.

Após a criação da tabela vamos retornar ao nosso fluxo.
(1) Duplo clique no componente;
(2) Na aba Connection Manager;
(3) Selecionar a conexão nova que criamos;
(4) Caso não exista a conexão é possível cria-la;
(5) Selecionar o formato de carga de dados;
(6) Selecionar a tabela criada;
(7) Caso não exista a tabela é possível cria-la;
(8) É possível visualizar os dados;
(9) Clicar em OK confirmar.

Novamente no componente de destino, vamos realizar o mapeamento das colunas.
(1) Componente de Destino;
(2) Aba Mappings;
(3) Origem e destino dos dados;
(4) Clicando com o botão direito do mouse é possível solicitar o mapeamento por igualdade de nomes;
(5) Clicar em OK para finalizar.

Observe que mesmo concluindo a configuração o componente ainda apresenta erro (4) quando executamos.
Analisando com mais detalhes, consegui compreender onde está o erro. Vamos juntos nessa investigação.
(1) Indicativo de componente em execução;
(2) Fluxo;
(3) Indicativo do erro;
(4) Local que ocorreu o erro;
(5) Clicar sobre a conexão e apertar F4;
(6) Configuração errada.

Podemos visualizar o erro clicando na aba Progress.

Da mesma forma como realizamos a configuração de Delay Validation, quando trabalhamos com tabelas temporárias no SSIS existe uma configuração que é primordial que poucos lembram que ela existe.
Essa configuração faz com que apenas uma conexão seja aberta em cada conexão.
Vamos voltar ao nosso fluxo para explicar melhor isso.
Observem as três setas. No primeiro
A primeira quando executada cria uma tabela temporária, ao concluir inicia o processamento da segunda seta que quando concluído inicia o processamento da terceira seta.

Lembrando que em todos os três momentos estamos utilizando uma conexão com o banco tempdb e fazendo uso de uma tabela temporária.
Se você não alterar a configuração da conexão com o tempdb, serão abertas e fechadas três conexões como banco.
Observação: Abrir e fechar uma conexão com o banco de dados em cada componente é um comportamento default de todos os componentes que utilizam conexão com Microsoft SQL Server, mais somente gera erros quando trabalhamos com objetos temporários, pois eles são eliminados sempre que a sessão é encerrada.
Tá mais o que isso pode gerar de impactante? Muito simples, basta você lembrar dos conceitos de tabelas temporárias. Na documentação diz que a vida útil de uma tabela temporária está condicionada principalmente ao tempo em que a sessão em que ela foi criada estiver ativa, ou seja, voltando na nossa imagem, quando o fluxo inicia na primeira seta, uma conexão é aberta, a tabela temporária é criada e após isso a sessão é eliminada pois o componente concluiu seu processamento, fazendo com que a tabela temporária seja eliminada, o que vai gerar erro na segunda seta pois ela irá depender desse objeto.
Beleza, entendi! Mais como podemos resolver esse problema de configuração?
Fique tranquilo, não é um bicho de sete cabeças! Sempre que estamos trabalhando com tabelas temporárias, a conexão que é usada com o banco TempDB deve ter a sua propriedade Retain Same Connection alterada de False para True.
Basta clicar sobre a conexão, apertar o botão F4 e no item (6) alterar de False pra True.
Caso não esteja, toda vez que ele passar por um componente que faz a utilização dessa conexão ela é iniciada e quando ele termina a sua execução ele finaliza.
Em nosso caso, o primeiro passo do nosso processo é criar uma tabela temporária e durante o seu processamento essa tabela deverá estar criada somente ao termino de todo o fluxo que ela deve ser descartada.
Podemos observar que após a alteração da propriedade da conexão o fluxo funcionou com sucesso.
(1) Fluxo executado com sucesso;
(2) Mensagem indicando sucesso na execução;
Observem que todos os registros caíram no fluxo de existência, foram carregados na tabela temporária e por último atualizados com sucesso.

Vou realizar uma alteração para poder apresentar um pedaço dos dados sendo carregados diretamente na tabela final e outro bloco na tabela temporária.
Para que isso ocorra, vou excluir os registros existentes para o estado do Rio de Janeiro (SG_UF 'RJ').
(1) Conectar no servidor de banco de dados;
(2) Selecionar o banco de dados;
(3) Consultar para saber quantos dados existem para o Rio de Janeiro;
(4) Total de registros;
(5) Comando para eliminar os dados do Rio de Janeiro.

Execução do fluxo após eliminação dos dados.
(1) Fluxo executado com sucesso;
(2) Total de registros;
(3) Registros inexistentes e cadastrados;
(4) Registros existentes e atualizados.

Os arquivos usados até aqui estão disponíveis em:
Pacote SSIS - Lookup
12_Importa_Cargos_Lookup_Insert_Update.dtsx
12_Importa_Cargos_Lookup_Insert.dtsx
6 - Conclusão
Meu amigo terminamos assim mais um super post.
Quando falamos de Lookup, estamos falando do componente de maior importância no meu ponto de vista dentro do SSIS e é o que mais utilizo em meus fluxos de dados.
Espero que tenha conseguido transmitir para você a sua importância e sua aplicabilidade dentro de um ETL.
Nos encontramos no próximo post, um excelente dia e fique com Deus!
Commentaires